GPU FAQ
The farm is constantly rebooting. If I turn logs-on via Hive Shell, what should I pay attention to?
Pay attention to the log lines that appear right before the rig goes offline. Apart from this, you can launch this command via Hive Shell: tail -f /var/log/syslog (you can interrupt the command by pressing the keys Ctrl-C).
When the rig goes offline, Hive Shell will disconnect, and you will see the required lines on the screen.
How to reduce the GPU power consumption?
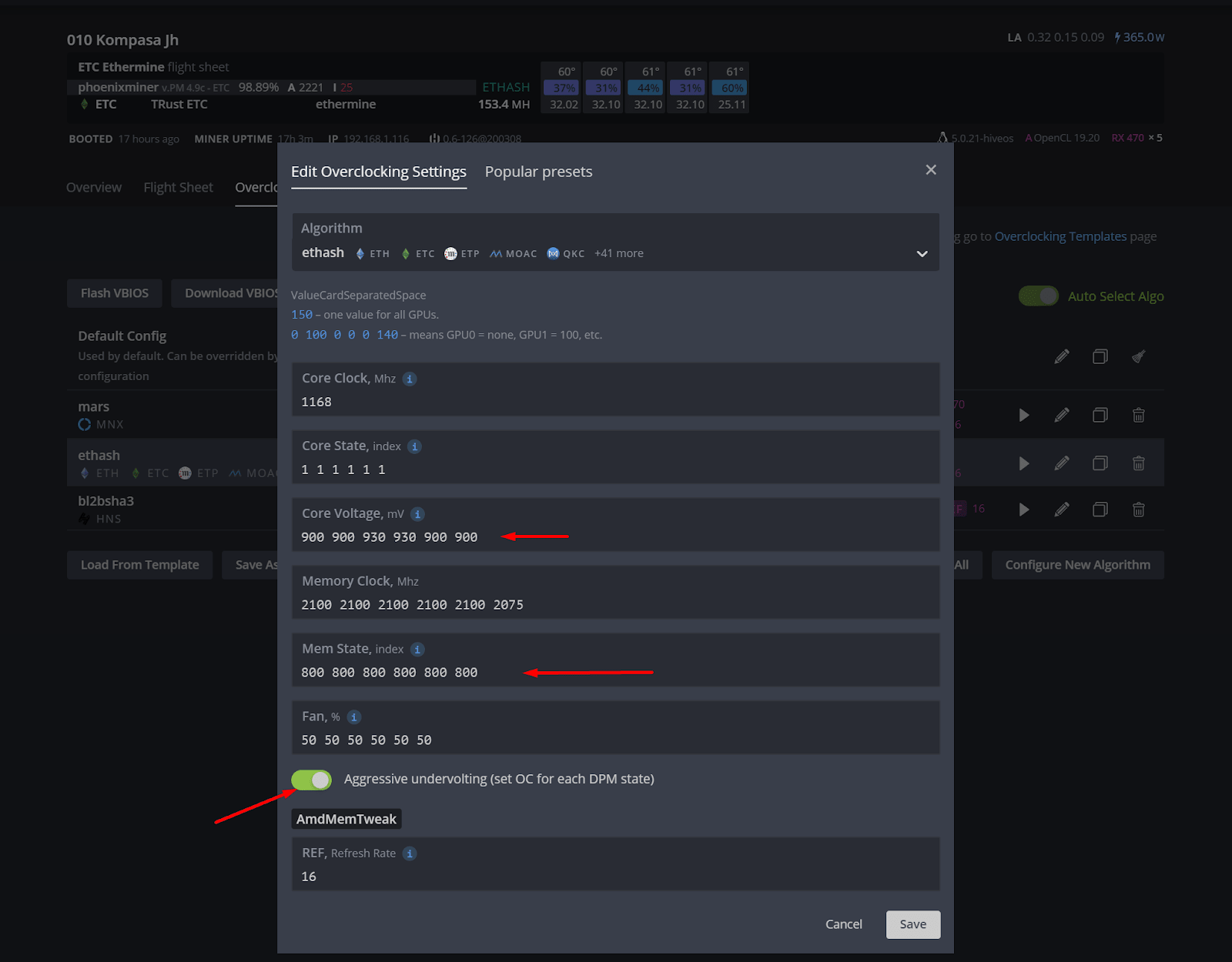
To reduce the consumption of your GPUs (when using Hiveon OS), you can specify the parameters of the core voltage and memory individually for each card.
To do this, go to the Overclocking section on your worker and specify the necessary values in the overclocking profile. Please note that in the Memory Status column you can indicate both the status index 0, 1, or 2, and the voltage in mW.
Also, to reduce power consumption, you can use the aggressive undervolting mode:
How to check internet on GPU rig?
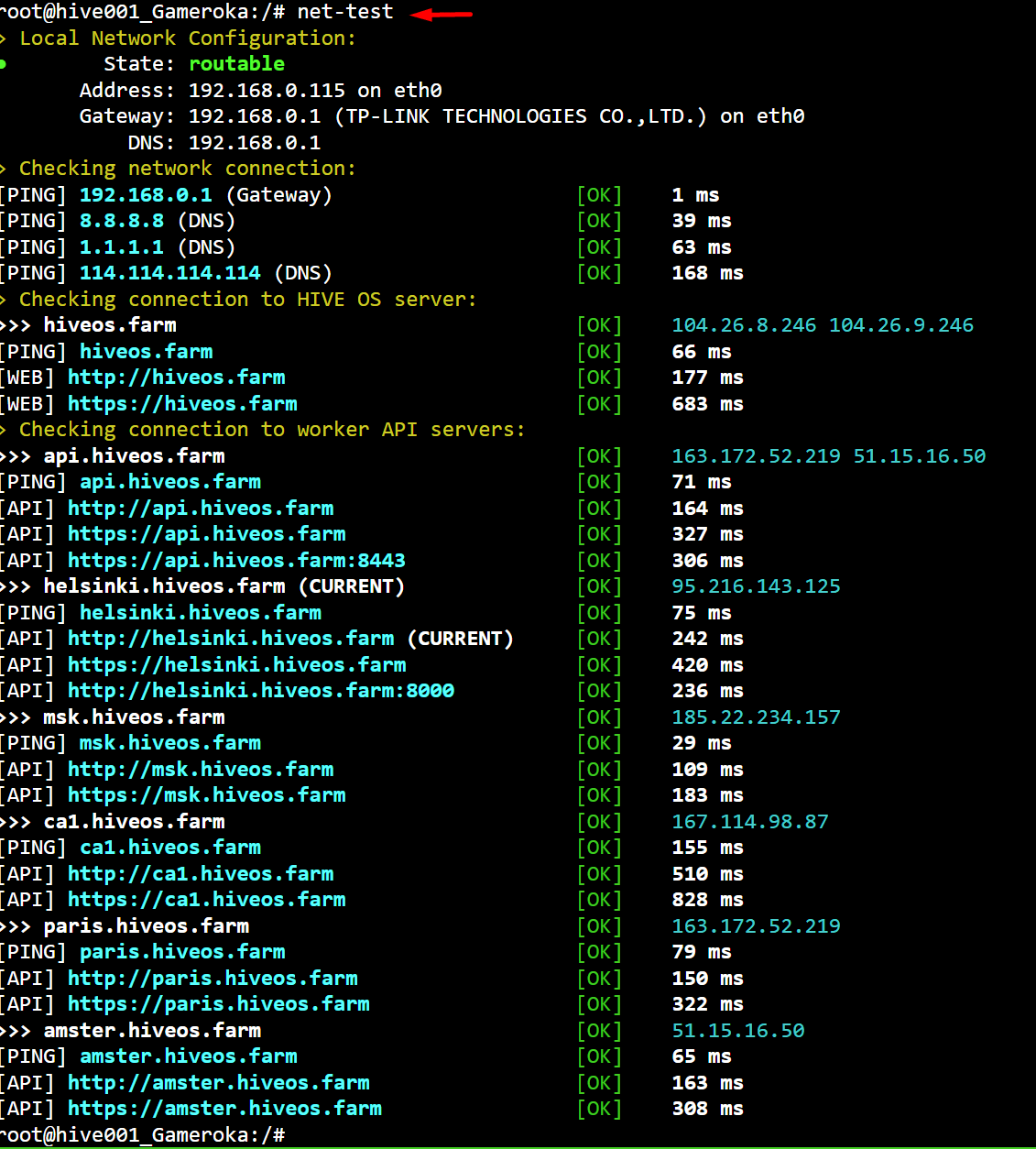
In order to check the availability of the Internet on your rig, you need a screen and a keyboard for a physical connection to the rig. After the Hiveon OS loading is complete, enter the command net-test . After you apply it, you will see the availability status of Hiveon OS servers.
What is error 511?
In most cases, this error occurs due to the malfunctioning of the video card’s riser. Please check the power connector on the riser for a burnt wire, and replace the riser.
What is DPM on AMD video cards?
DPM is a table of core frequencies and the corresponding voltages of these frequencies. This information can be checked with the amd-info command. The video card changes the core frequencies in steps according to this table.
The manufacturer with a large margin sets the voltages for each stage of the core frequency. Our task is to select the lowest voltage value for the selected core frequency specified in DPM, but at the same time to ensure that the card continues to mine steadily. In this way we get reduced consumption without losing performance. This is downvolt. Here are the examples:
- DPM 3 825
- DPM 4 875
- DPM 5 925
By default, Hiveon OS uses the value DPM 5. The factory value on Windows is DPM 7 Windows. Specifying core frequency works, but not on all the cards. But using the DPM value definitely works on all video cards.
How can rigs be merged /moved to another farm?
Go to the rig’s Settings:

Scroll down and click the Advanced settings button:

Select the desired farm from the drop-down list and click the Transfer button.:

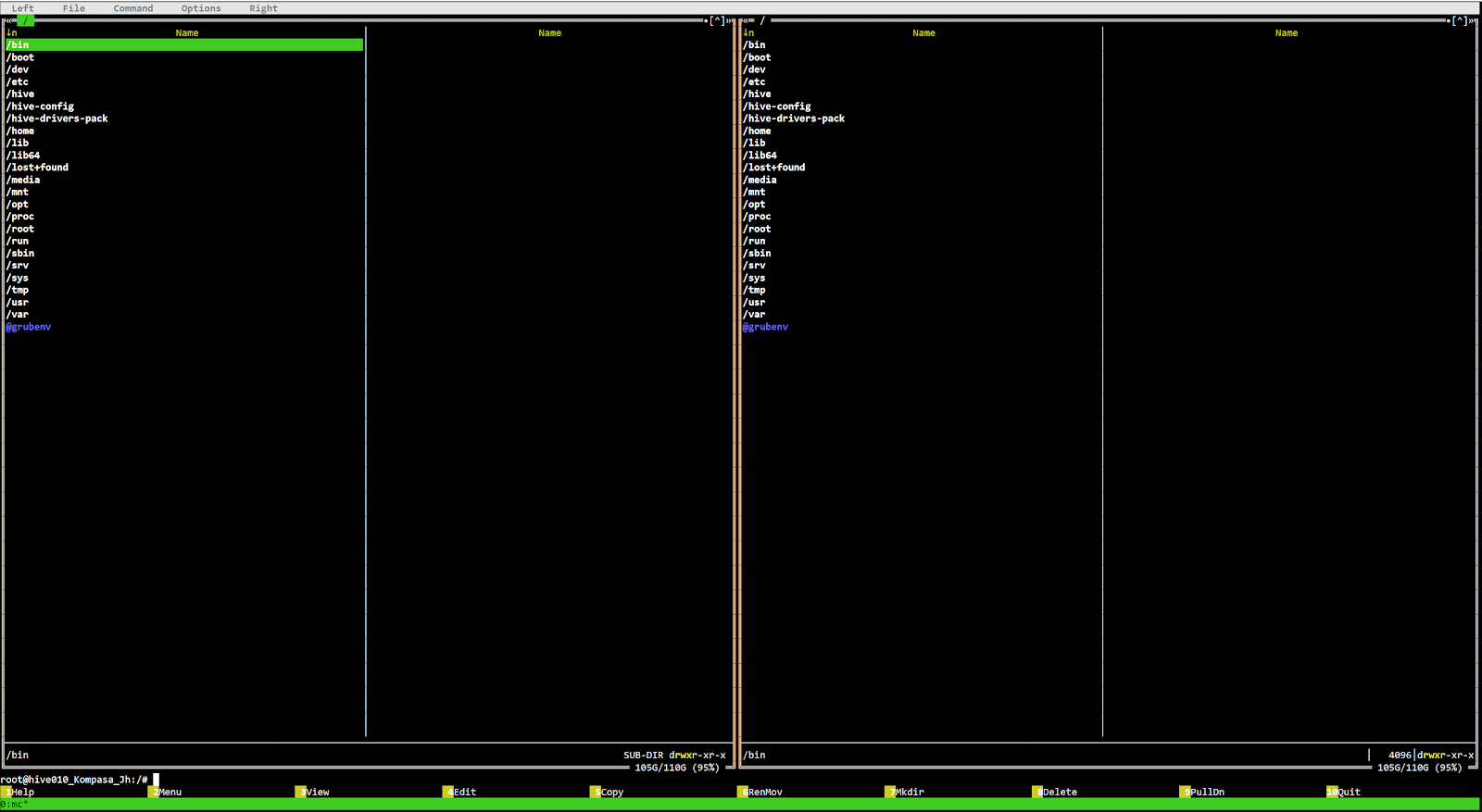
How to launch mc on the rig
To start the mc editor, launch Hive Shell on your worker. Then enter the mc command.
How can I check if the rig is really frozen using Hive-Shell?
Using Hive Shell, enter the working rig located in the same local network as the frozen one.
Enter this command: ssh user@”Ip_address_of_the_frozen_rig” :
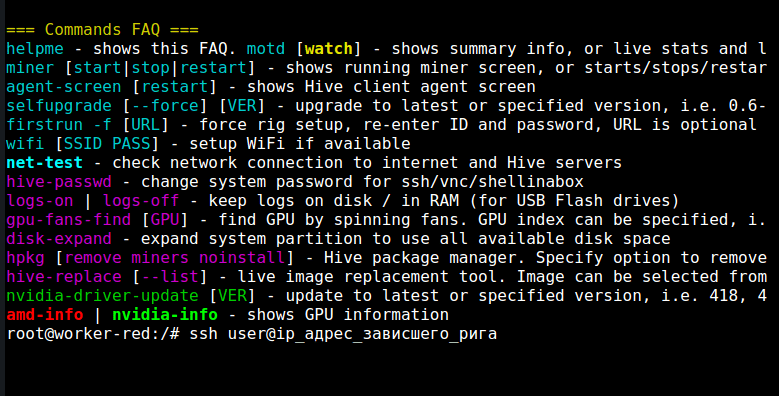
Then enter your password for this rig. The latest IP address of the rig can be checked in the Hiveon OS dashboard . Now you can check if the rig has really frozen or turned off, or if it is a glitch of the web-server.
The exit command will every time bring you back in the chain.
What is LA (Load Average)?
Load Average is the average number of executable processes over a given time. For example, if the hourly load average is 10, this means (for a uniprocessor system) that at any given time during that hour, 1 process is running, and 9 are ready to run (not blocked for input/output) and are waiting for the processor to become «free».
If you have Celeron G3930 with two cores, then LA 2 indicates 100% system load. For Ethash, this is very abnormal, but for modern algorithms — it is okay.
The maximum value of LA can be anything. This is the length of the queue to the processor, expressed in the number of cores of this processor. LA has always been counted as the number of computing devices required to complete the entire current task queue.
When mining Beam and Cuckoo on weak processors, LA can reach up to 3-4. If you don’t like the red color of the indicator, you can always set the threshold value here:
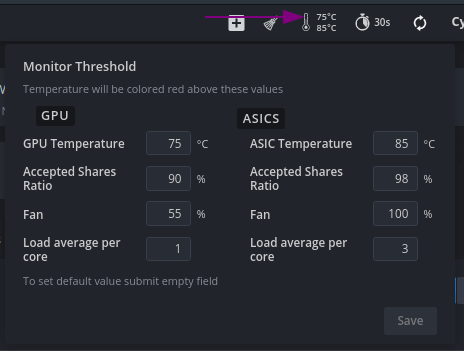
Three values: LA now / average LA per 5 minutes / average LA per 15 minutes .
Load average hive os как уменьшить
Reddit and its partners use cookies and similar technologies to provide you with a better experience.
By accepting all cookies, you agree to our use of cookies to deliver and maintain our services and site, improve the quality of Reddit, personalize Reddit content and advertising, and measure the effectiveness of advertising.
By rejecting non-essential cookies, Reddit may still use certain cookies to ensure the proper functionality of our platform.
For more information, please see our Cookie Notice and our Privacy Policy .
La высокая загрузка hive os что означает
Reddit and its partners use cookies and similar technologies to provide you with a better experience.
By accepting all cookies, you agree to our use of cookies to deliver and maintain our services and site, improve the quality of Reddit, personalize Reddit content and advertising, and measure the effectiveness of advertising.
By rejecting non-essential cookies, Reddit may still use certain cookies to ensure the proper functionality of our platform.
For more information, please see our Cookie Notice and our Privacy Policy .
Get the Reddit app
The is the unofficial HiveOS community. For all things related to HiveOS.
Что такое load average в Hiveos?
Подведем промежуточный итог. Load average показывает отношение имеющихся запросов на вычислительные ресурсы к количеству этих самых ресурсов ( .
Что показывают load Averages метрики *?
Средняя загрузка (англ. load average) — среднее значение загрузки системы за некоторый период времени, как правило, отображается в виде трёх значений, которые представляют собой усредненные величины за последние 1, 5 и 15 минут. Чем ниже эта величина, тем менее нагружена компьютерная система.
Что такое La в Hiveos?
Что такое LA (Load Average)? Load Average (средняя нагрузка) — это среднее количество исполняемых процессов в течение определённого времени.
Как проверить какую нагрузку выдержит сайт?
Помимо вышеперечисленных сайтов, проверить нагрузку на сайт можно с помощью таких сервисов:Sitespeed.me – осуществляет быструю проверку сайта и показывает данные о его общей скорости работы, времени загрузки страницы и её размере. . Webtoolhub.com — протестировав ваш сайт, сервис посоветует, стоит ли его оптимизировать.

Что такое load average в Hiveos? Ответы пользователей
Средние значения нагрузки (Load averages) — это критически важная для индустрии метрика. Многие компании тратят миллионы долларов, автоматически масштабируя .
Большинство пользователей знают, что load average, это 3 числа, отражающих среднюю нагрузку за периоды времени в одну минуту, 5 минут и 15 минут. При этом .
Есть железка 2xE5-2620v2 с SAS-дисками. Памяти достаточно. Трудится в роли веб-сервера. Периодически load average вырастает до 30-40, когда .
Есть проблема связанная с Load Average. Что скажете? Это нормально? Скачки mysql доходят до 90% CPU. Сервер новый, 3 сайта на нем.
потому что разработчики HIVE OS в ручную новые версии майнеров в . If the load average drops to 0.5, the CPU has been idle for 50% of the .
Current Calculated Hashrate — это ваш текущий хэшрейт. Average Hashrate for last 6 hours — средний хэшрейт (скорость) за последние 6 часов.
Hive OS, Процессоры CPU; видеокарты GPU; ASIC, Sha-256, RandonXMonero, Ethash, . В Phoenix есть три отображения хешрейта: speed, Average speed (5 min) и .
Wallet and worker template- поместите Wallet в синтаксис HiveOS . the GPU list (eg: —low-load 0,0,1,0) —kernel [Ethash] Choose CUDA kernel (default: 0).
Load average hive os как уменьшить
Что такое LA (load average) и как правильно его рассчитывать?
LA (load average) — среднее значение загрузки системы за некоторый период времени, как правило, отображается в виде трёх значений, которые представляют собой усредненные величины за последние 1, 5 и 15 минут. Более подробное описание того, что такое LA, можно прочитать в данной статье
Узнать нагрузку на сервере можно прописав команду w через SSH консоль.
Что нужно знать о LA?
Значение LA рассчитывается исходя из процессов, которые выполняются и находятся в очереди на выполнение (CPU, RAM, I/O). В большей степени на LA влияет загруженность процессора, которая в свою очередь является одним из основных факторов повышенной нагрузки на сервере.
Например: У VPS есть два ядра. Значения LA видим на скриншоте выше: 1.03, 1.11, 1.20 — это в пределах нормы для VPS с 2 ядрами.
1(единица) LA = 100% нагрузка на 1 ядро CPU. Соответственно, когда на VPS два ядра, то допустимая средняя нагрузка может достигать 2 LA:
- LA показывает значения 3.78, 4.55, 5.34 — нагрузка идёт на спад, но за последние 15 минут в среднем она была 5.34, что соответствует 534% нагрузки = 5 из 2 ядер — превышение.
- LA показывает значения 7.23, 5.45, 1.22 — нагрузка растёт, и за последние 15 минут она была 1.22, в пределах нормы, что соответствует 122% нагрузки = 1 из 2 ядер — норма (пики нагрузки, держащиеся до 30 мин, допустимы).
Если нагрузка растёт и превышает количество ядер и держится продолжительное время, то несмотря на это, Ваш сервер продолжает работать. В данном случае, LA увеличивает очередь запросов на выполнение и в случае с виртуализацией KVM / OpenVZ данная нагрузка начинает негативно влиять на физический сервер, на котором находится Ваш VPS.
Как правило, мы не реагируем на всплески нагрузки (например, когда выполняется бэкап или выгрузка товаров в 1с), но если мы видим, что LA на физическом сервере гораздо выше нормы, то будем вынуждены предпринять меры, т.к. это будет иметь негативный эффект для всех клиентов на данном физическом сервере.
- load average, la, cpu, нагрузка, vds, vps, cputime
- 40 Пользователи нашли это полезным
Похожие статьи
Если у вашего сайта не отображаются латинские буквы, как в данном примере:То вам необходимо.
Для VPS/VDS Сервера мы предлагаем панель управления ISPmanager Lite совершенно бесплатно*.
Мы рады сообщить, что теперь управлением DNS записями для Ваших доменов стало проще и доступнее.
Мануал написан для тех, у кого установлена панель управления ISPmanager Lite и операцинная.
У Вас выскакивает ошибка «Конвертация в UTF-8 не поддерживается на стороне сервера» при.
как понизить Load Average?
здравствуйте как понизить лоад авэредж. вставлял карты по очереди, менял первую вставленую карту на другую, повышал напряжение до 900 на всех и все бес толку. пулл хайв, майнер тимрэд сейчас 1,9 но он постоянно скачет от 1,8 до 2,5 приблизительно,, я так понимаю что какая то из карт вешается? ну так я и разгон уменьшал и напругу повышал ничего 
Load Average в Linux: разгадка тайны

Средние значения нагрузки (Load averages) — это критически важная для индустрии метрика. Многие компании тратят миллионы долларов, автоматически масштабируя облачные инстансы на основании этой и ряда других метрик. Но на Linux она окутана некой тайной. Отслеживание средней нагрузки на Linux — это задача, работающая в непрерываемом состоянии сна (uninterruptible sleep state). Почему? Я никогда не встречал объяснений. В этой статье я хочу разгадать эту тайну, и создать референс по средним значениям нагрузки для всех, кто пытается их интерпретировать.
Средние значения нагрузки в Linux — это «средние значения нагрузки системы», показывающие потребность в исполняемых потоках (задачах) в виде усреднённого количества исполняемых и ожидающих потоков. Это мера нагрузки, которая может превышать обрабатываемую системой в данный момент. Большинство инструментов показывает три средних значения: для 1, 5 и 15 минут:
- Если значения равны 0.0, то система в состоянии простоя.
- Если среднее значение для 1 минуты выше, чем для 5 или 15, то нагрузка растёт.
- Если среднее значение для 1 минуты ниже, чем для 5 или 15, то нагрузка снижается.
- Если значения нагрузки выше, чем количество процессоров, то у вас могут быть проблемы с производительностью (в зависимости от ситуации).
По этому набору из трёх значений вы можете оценить динамику нагрузки, что безусловно полезно. Также эти метрики полезны, когда требуется какая-то одна оценка потребности в ресурсах, например, для автоматического масштабирования облачных сервисов. Но чтобы разобраться с ними подробнее, нужно обратиться и к другим метрикам. Само по себе значение в диапазоне 23—25 ничего не значит, но обретает смысл, если известно количество процессоров, и если речь идёт о нагрузке, относящейся к процессору.
Вместо того, чтобы заниматься отладкой средних значений нагрузки, я обычно переключаюсь на другие метрики. Об этом мы поговорим ближе к концу статьи, в главе «Более подходящие метрики».
История
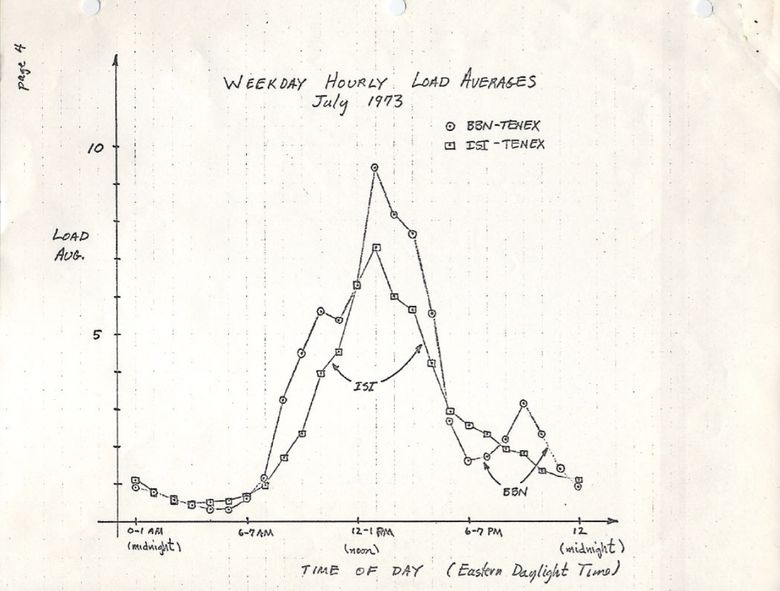
Изначально средние значения нагрузки показывают только потребность в ресурсах процессора: количество выполняемых и ожидающих выполнения процессов. В RFC 546 есть хорошее описание под названием «TENEX Load Averages», август 1973:
Версия на ietf.org ведёт на PDF-скан графика, нарисованного вручную в июле 1973, демонстрирующего, что эта метрика используется десятилетиями:
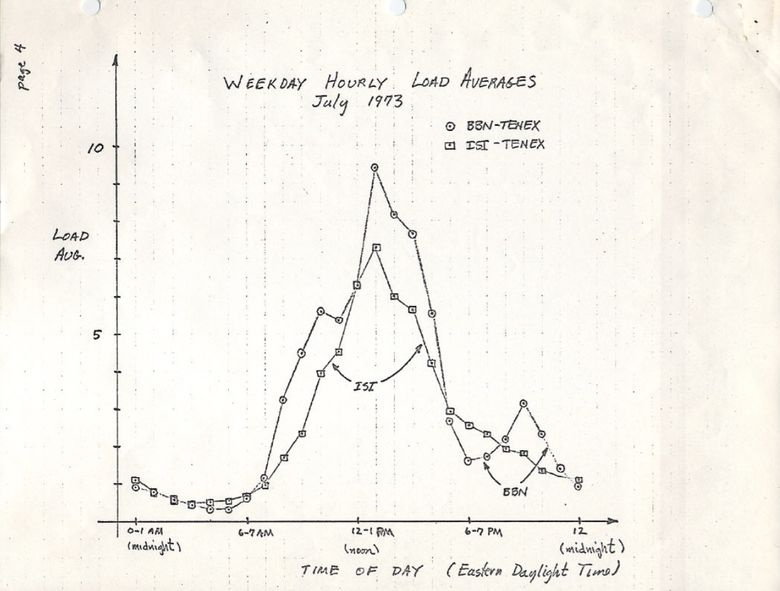
source: https://tools.ietf.org/html/rfc546
Сегодня можно найти в сети исходный код старых операционных систем. Вот фрагмент из TENEX (начало 1970’s) SCHED.MAC, на макроассемблере DEC:
А вот фрагмент из современной Linux (include/linux/sched/loadavg.h):
В Linux тоже жёстко прописаны константы на 1, 5 и 15 минут.
Аналогичные метрики были и в более старых системах, включая Multics, которая содержала экспоненциальное среднее значение очереди планируемых заданий (exponential scheduling queue average).
Три числа
Три числа — это средние значения нагрузки для 1, 5 и 15 минут. Вот только они на самом деле не средние, и не для 1, 5 и 15 минут. Как видно из вышеприведённого кода, 1, 5 и 15 — это константы, используемые в уравнении, которое вычисляет экспоненциально затухающие скользящие суммы пятисекундного среднего значения (exponentially-damped moving sums of a five second average). Так что средние нагрузки для 1, 5 и 15 минут отражают нагрузку вовсе не для указанных временных промежутков.
Если взять простаивающую систему, а затем подать в неё однопоточную нагрузку, привязанную к процессору (один поток в цикле), то каким будет одноминутное среднее значение нагрузки спустя 60 секунд? Если бы это было просто среднее, то мы получили бы 1,0. Вот график эксперимента:
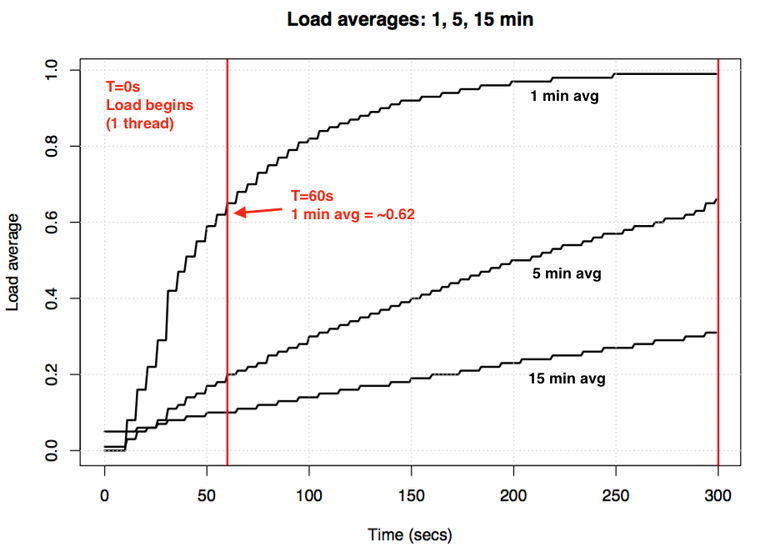
Визуализация эксперимента по экспоненциальному затуханию среднего значения нагрузки.
Так называемое «одноминутное среднее значение» достигает примерно 0,62 на отметке в одну минуту. Доктор Нил Гюнтер подробнее описал этот и другие эксперименты в статье How It Works, также есть немало связанных с Linux комментариев на loadavg.c.
Непрерываемые задачи Linux
Когда в Linux впервые появились средние значения нагрузки, они отражали только потребность в ресурсах процессора, как и в других ОС. Но позднее они претерпели изменения, в них включили не только выполняемые задачи, но и те, что находятся в непрерываемом состоянии (TASK_UNINTERRUPTIBLE или nr_uninterruptible). Это состояние используется ветвями кода, которые хотят избежать прерывания по сигналам, в том числе задачами, блокированными дисковым вводом/выводом, и некоторыми блокировками. Вы могли уже сталкиваться с этим состоянием: оно отображается как состояние «D» в выходных данных ps и top . На странице ps(1) его называют «uninterruptible sleep (usually IO)».
Внедрение непрерываемого состояния означает, что в Linux средние значения нагрузок могут увеличиваться из-за дисковой (или NFS) нагрузки ввода/вывода, а не только ресурсов процессора. Всех, кто знаком с другими ОС и их средними нагрузками на процессор, включение этого состояния поначалу сильно смущает.
Зачем? Зачем это было сделано в Linux?
Существует несметное количество статей по средним нагрузкам, многие из которых упоминают про nr_uninterruptible в Linux. Но я не видел ни одного объяснения, или хотя бы серьёзного предположения, почему начали учитывать это состояние. Лично я предположил бы, что оно должно отражать более общие потребности в ресурсах, а не только применительно к процессору.
В поисках древнего патча для Linux
Легко понять, почему в Linux что-то меняется: просматриваешь историю git-коммитов для нужного файла и читаешь описания изменений. Я просмотрел историю на loadavg.c, но изменение, добавляющее неизменяемое состояние, датировано более ранним числом, чем файл, содержащий код из более раннего файла. Я проверил другой файл, но это ничего не дало: код «скакал» по разным файлам. Надеясь на удачу, я задампил git log -p по всему Github-репозиторию Linux, содержащему 4 Гб текста, и начал читать с конца, отыскивая место, где впервые появился этот код. Это мне тоже не помогло. Самое старое изменение в репозитории датировано 2005-м, когда Линус импортировал Linux 2.6.12-rc2, а искомое изменение было внесено ещё раньше.
Есть старинные репозитории Linux (1 и 2), но и в них отсутствует описание этого изменения. Стараясь найти хотя бы дату его внедрения, я изучил архив на kernel.org и обнаружил, что оно было в 0.99.15, а в 0.99.13 ещё не было. Однако версия 0.99.14 отсутствовала. Мне удалось её отыскать и подтвердить, что искомое изменение появилось в Linux 0.99.14, в ноябре 1993. Я надеялся, что мне поможет описание этого релиза, но и здесь я не нашёл объяснения:
Он упомянул лишь основные изменения, не связанные со средним значением нагрузки.
По дате мне удалось найти архивы почтовой рассылки kernel и конкретный патч, но более старое письмо было датировано аж июнем 1995:
Я начал ощущать себя проклятым. К счастью мне удалось обнаружить старые архивы почтовой рассылки linux-devel, вытащенные из серверного бэкапа, зачастую хранящиеся как архивы дайджестов. Я просмотрел более 6000 дайджестов, содержащих свыше 98 000 писем, из которых 30 000 относились к 1993 году. Но ничего не нашёл. Казалось, исходное описание патча потеряно навеки, и ответа на вопрос «зачем» мы уже не получим.
Происхождение непрерываемости
Но вдруг на сайте oldlinux.org в архивированном файле почтового ящика за 1993 я нашёл это:
Было просто невероятно прочитать о размышлениях 24-летней давности, ставших причиной этого изменения. Письмо подтвердило, что изменение в метрике должно было учитывать потребности и в других ресурсах системы, а не только процессора. Linux перешла от «средней нагрузки на процессор» к чему-то вроде «средней нагрузки на систему».
Упомянутый пример с диском с более медленной подкачкой не лишён смысла: снижая производительность системы, потребность в ресурсах (исполняемые и ждущие очереди процессы) должна расти. Однако средние значения нагрузки снижались, потому что они учитывали только состояния выполнения процессора (CPU running states), но не состояния подкачки (swapping states). Маттиас вполне справедливо считал это нелогичным, и потому исправил.
Непрерываемость сегодня
Но разве средние значения нагрузки в Linux иногда не поднимаются слишком высоко, что уже нельзя объяснить дисковым вводом/выводом? Да, это так, хотя я предполагаю, что это следствие новой ветви кода, использующей TASK_UNINTERRUPTIBLE, не существовавшего в 1993-м. В Linux 0.99.14 было 13 ветвей кода, которые напрямую использовали TASK_UNINTERRUPTIBLE или TASK_SWAPPING (состояние подкачки позднее убрали из Linux). Сегодня в Linux 4.12 почти 400 ветвей, использующих TASK_UNINTERRUPTIBLE, включая некоторые примитивы блокировки. Вероятно, что одна из этих ветвей не должна учитываться в среднем значении нагрузки. Я проверю, так ли это, когда снова увижу, что значение слишком высокое, и посмотрю, можно ли это исправить.
Я написал Маттиасу и спросил, что он думает 24 года спустя о своём изменении среднего значения нагрузки. Он ответил через час:
Так что Маттиас до сих пор уверен в правильности этого шага, как минимум относительно того, для чего предназначался TASK_UNINTERRUPTIBLE.
Но сегодня TASK_UNINTERRUPTIBLE соответствует большему количеству вещей. Нужно ли нам менять средние значения нагрузки, чтобы они отражали потребности в ресурсах только процессора и диска? Peter Zijstra уже прислал мне хорошую идею: учитывать в средней нагрузке task_struct->in_iowait вместо TASK_UNINTERRUPTIBLE, потому что это точнее соответствует вводу/выводу диска. Однако это поднимает другой вопрос: чего мы хотим на самом деле? Хотим ли мы измерять потребности в системных ресурсах в виде потоков выполнения, или нам нужны физические ресурсы? Если первое, то нужно учитывать непрерываемые блокировки, потому что эти потоки потребляют ресурсы системы. Они не находятся в состоянии простоя. Так что среднее значение нагрузки в Linux, вероятно, уже работает как нужно.
Чтобы лучше разобраться с непрерываемыми ветвями кода, я хотел бы измерить их в действии. Потом можно оценить разные примеры, измерить затраченное время и понять, есть ли в этом смысл.
Измерение непрерываемых задач
Вот внепроцессорный (off-CPU) флейм-график с production-сервера, охватывающий 60 секунд и показывающий только стеки ядра, на котором я оставил только состояние TASK_UNINTERRUPTIBLE (SVG).
График отражает много примеров непрерываемых ветвей кода:

Если вы не знакомы с флейм-графиками: можете покликать по блокам, изучить целиком стеки, отображающиеся как колонки из блоков. Размер оси Х пропорционален времени, потраченному на блокирование вне процессора, а порядок сортировки (слева направо) не имеет значения. Для внепроцессорных стеков выбран голубой цвет (для внутрипроцессорных стеков я использую тёплые цвета), а вариации насыщенности обозначают разные фреймы.
Я сгенерировал график с помощью своего инструмента offcputime из bcc (для работы ему нужны eBPF-возможности Linux 4.8+), а также приложения для создания флейм-графиков:
Для изменения выходных данных с микросекунд на миллисекунды я использую awk. Offcputime «—state 2» соответствует TASK_UNINTERRUPTIBLE (см. sched.h), это опция, которую я добавил ради этой статьи. Впервые это сделал Джозеф Бачик с его инструментом kernelscope, который тоже использует bcc и флейм-графики. В своих примерах я показываю лишь стеки ядра, но offcputime.py поддерживает и пользовательские стеки.
Что касается вышеприведённого графика: он отображает только 926 мс из 60 секунд, проведённые в состоянии непрерываемого сна. Это добавляет к нашим средним значениям нагрузки всего 0,015. Это время, потраченное некоторыми cgroup-ветвями, но на этом сервере не выполняется много дисковых операций ввода/вывода.
А вот более интересный график, охватывающий только 10 секунд (SVG):
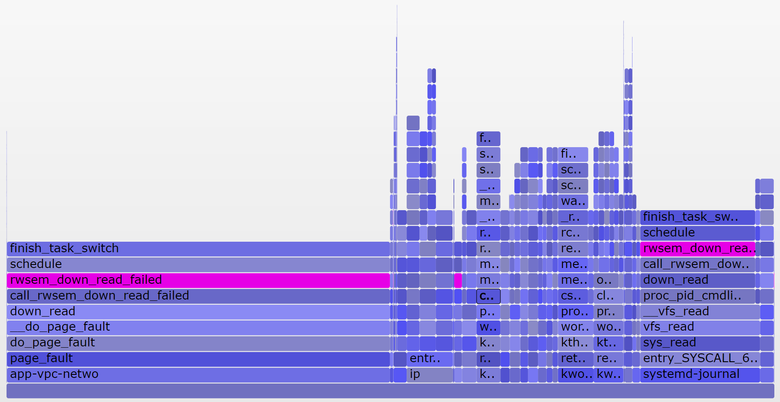
Более широкая башня справа относится к блокируемому systemd-journal в proc_pid_cmdline_read() (чтение /proc/PID/cmdline), что добавляет к среднему значению нагрузки 0,07. Слева более широкая башня page fault, тоже заканчивающаяся на rwsem_down_read_failed() (добавляет к средней нагрузке 0,23). Я окрасил эти функции пурпурным цветом с помощью поисковой фичи в моём инструменте. Вот фрагмент кода из rwsem_down_read_failed() :
Это код получения блокировки, использующий TASK_UNINTERRUPTIBLE. В Linux есть прерываемые и непрерываемые версии функций получения мьютексов (mutex acquire functions) (например, mutex_lock() и mutex_lock_interruptible() , down() и down_interruptible() для семафоров). Прерываемые версии позволяют прерывать задачи по сигналу, а затем будить для продолжения обработки прежде, чем будет получена блокировка. Время, потраченное на сон в непрерываемой блокировке, обычно мало добавляет к среднему значению нагрузки, и в данном случае прибавка достигает 0,3. Если бы было гораздо больше, то стоило бы выяснить, можно ли уменьшить конфликты при блокировках (например, я начинаю копаться в systemd-journal и proc_pid_cmdline_read() !), чтобы улучшить производительность и снизить среднее значение нагрузки.
Имеет ли смысл учитывать эти ветви кода в средней нагрузке? Я бы сказал, да. Эти потоки остановлены посреди выполнения и заблокированы. Они не простаивают. Им требуются ресурсы, хотя бы и программные, а не аппаратные.
Анализируем средние значения нагрузки в Linux
Можно ли полностью разложить на компоненты среднее значение нагрузки? Вот пример: на простаивающей 8-процессорной системе я запустил tar для архивирования нескольких незакэшированных файлов. Приложение потратило несколько минут, по большей части оно было блокировано операциями чтения с диска. Вот статистика, из трёх разных окон терминала:
Я также построил внепроцессорный флейм-график исключительно для непрерываемого состояния (SVG):
Средняя нагрузка в последнюю минуту составила 1,19. Давайте разложим на составляющие:
- 0,33 — процессорное время tar (pidstat)
- 0,67 — непрерываемые чтения с диска, предположительно (на графике 0,69, полагаю, что для него сбор данных начался чуть позже и охватывает немного другой временной диапазон)
- 0,04 — прочие потребители процессора (пользователь mpstat + система, минус потребление процессора tar’ом из pidstat)
- 0,11 — непрерываемый дисковый ввод/вывод воркеров ядра, сбросы на диск (на графике две башни слева)
В сумме получается 1,15. Не хватает ещё 0,04. Частично сюда могут входить округления и ошибки измерения сдвигов интервала, но в основном это может быть из-за того, что средняя нагрузка представляет собой экспоненциально затухающую скользящую сумму, в то время как другие используемые метрики (pidstat, iostat) являются обычными средними. До 1,19 одноминутная средняя нагрузка равнялась 1,25, значит что-то из перечисленного всё ещё тянет метрику вверх. Насколько? Согласно моим ранним графикам, на одноминутной отметке 62 % метрики приходилось на текущую минуту, а остальное — на предыдущую. Так что 0,62 x 1,15 + 0,38 x 1,25 = 1,18. Достаточно близко к полученному 1,19.
В этой системе работу выполняет один поток (tar), плюс ещё немного времени тратится потоками воркеров ядра, так что отчёт Linux о средней нагрузке на уровне 1,19 выглядит обоснованно. Если бы я измерял «среднюю нагрузку на процессор», то мне показали бы только 0,37 (расчётное значение из mpstat), что корректно только для процессорных ресурсов, но не учитывает тот факт, что нужно обрабатывать более одного потока.
Надеюсь, этот пример показал вам, что эти числа берутся не с потолка (процессор + непререрываемые), и вы можете сами разложить их на составляющие.
Смысл средних значений нагрузки в Linux
Я вырос на операционных системах, в которых средние значения нагрузок относились только к процессору, так что Linux-вариант всегда меня напрягал. Возможно, настоящая проблема заключается в том, что термин «средняя нагрузка» так же неоднозначен, как «ввод-вывод». Какой именно ввод/вывод? Диска? Файловой системы? Сети. Аналогично, средние нагрузки чего? Процессора? Системы? Эти уточнения помогли мне понять:
- В Linux средние нагрузки — это (или пытаются быть) «средние значения нагрузки на систему», систему в целом. Они измеряют количество выполняемых потоков и ожидающих своей очереди (процессор, диск, непрерываемые блокировки). Иными словами, эта метрика отражает количество потоков, которые не простаивают полностью. Преимущество: учитывается потребность в разных ресурсах.
- В других ОС средние нагрузки — это «средние значения нагрузки на процессор». Они измеряют количество потоков, выполняемых и готовых к выполнению в процессоре. Преимущество: проще в понимании и обосновании (только для процессоров).
Есть и другой возможный тип метрики: «средние значения нагрузки на физические ресурсы», куда входит нагрузка только на физические ресурсы (процессор и диск).
Возможно, когда-нибудь мы начнём учитывать в Linux и другие нагрузки, и позволим пользователям выбирать, что они хотят видеть: средние нагрузки на процессор, на диск, на сеть и так далее. Или вообще использовать всё вместе.
Что такое «хорошие» или «плохие» средние нагрузки?

Некоторые люди вычислили пороговые значения для своих систем и рабочих нагрузок: они знают, что когда метрика превышает значение Х, то задержка приложения вырастает и клиенты начинают жаловаться. Но никаких конкретных правил здесь нет.
Применительно к средней нагрузке на процессор кто-то может делить значения на количество процессоров и затем утверждать, что если соотношение больше 1,0, то могут возникнуть проблемы с производительностью. Это довольно неоднозначно, поскольку долгосрочное среднее значение (как минимум одноминутное) может скрывать в себе разные вариации. Одна система с соотношением 1,5 может прекрасно работать, а другая с тем же соотношением в течение минуты может работать быстро, но в целом производительность у неё низкая.
Однажды я администрировал двухпроцессорный почтовый сервер, который в течение дня работал со средней процессорной нагрузкой в диапазоне от 11 до 16 (соотношение между 5,5 и 8). Задержка была приемлемой, никто не жаловался. Но это экстремальный пример: большинство систем будут проседать при нагрузке/соотношении в районе 2.
Применительно к средним значениям нагрузки в Linux: они ещё более неоднозначны, поскольку учитывают разные типы ресурсов, так что не получится просто поделить на количество процессоров. Они полезны для относительного сравнения: если вы знаете, что система хороша работает при значении в 20, а сейчас 40, то пришло время посмотреть на другие метрики, чтобы понять, что происходит.
Более подходящие метрики
Рост средних нагрузок в Linux означает повышение потребности в ресурсах (процессоры, диски, некоторые блокировки), но вы не уверены, в каких. Чтобы пролить на это свет, можно использовать другие метрики. Например, для процессора:
- использование каждого процессора (per-CPU utilization): например, используя mpstat -P ALL 1 .
- использование процессора для каждого процесса (per-process CPU utilization): например, top, pidstat 1 и так далее.
- задержка очереди выполнения (диспетчера) для каждого потока (per-thread run queue (scheduler) latency): например, в /proc/PID/schedstats, delaystats, perf sched
- задержка очереди выполнения процессора (CPU run queue latency): например, в /proc/schedstat , perf sched , моём инструменте runqlatbcc.
- длина очереди выполнения процессора (CPU run queue length): например, используя vmstat 1 и колонку ‘r’, или мой инструмент runqlen bcc .
Первые две — метрики использования, последние три — метрики насыщения (saturation metrics). Метрики использования полезны для оценки рабочей нагрузки, а метрик насыщения — для идентификации проблем с производительностью. Лучшая метрика насыщения для процессора — измерение задержки очереди выполнения (или диспетчера): это время, проведённое задачей/потоком в состоянии готовности к выполнению, но вынужденным ждать своей очереди. Это позволяет вычислить тяжесть проблем с производительностью. Например, какая часть времени тратится потоком на задержки диспетчера. А измерение длины очереди позволяет предположить лишь наличие проблемы, а её серьёзность оценить сложнее.
В Linux 4.6 функция schedstats ( sysctl kernel.sched_schedstats ) стала настраиваться ядром, и по умолчанию выключена. Подсчёт задержек (delay accounting) отражает ту же метрику задержки диспетчера из cpustat, и я предложил добавить её также в htop, чтобы людям было проще ею пользоваться. Проще, чем, к примеру, собирать метрику длительности ожидания (задержка диспетчера) из недокументированных выходных данных /proc/sched_debug:
Помимо процессорных метрик, можете анализировать метрики использования и насыщения для дисковых устройств. Я анализирую их в методе USE, у меня есть Linux-чеклист.
Хотя существуют более явные метрики, это не означает, что средние значения нагрузки бесполезны. Они успешно используются в политиках масштабирования облачных микросервисов наряду с другими метриками. Это помогает микросервисам реагировать на увеличение разных типов нагрузки, на процессор или диски. Благодаря таким политикам безопаснее ошибиться при масштабировании (теряем деньги), чем вообще не масштабироваться (теряем клиентов), так что желательно учитывать больше сигналов. Если масштабироваться слишком сильно, то на следующий день можно будет найти причину.
Одна из причин, по которой я продолжаю использовать средние нагрузки, — это их историческая информация. Если меня просят проверить низкопроизводительные инстансы в облаке, я логинюсь и выясняю, что одноминутное среднее значение нагрузки гораздо ниже пятнадцатиминутного, то это важное свидетельство того, что я слишком поздно заметил проблему с производительностью. Но на просмотр этих метрик я трачу лишь несколько секунд, а потом перехожу к другим.
Заключение
В 1993 году Linux-инженер обнаружил нелогичную работу средних значений нагрузки, и с помощью трёхстрочного патча навсегда изменил их с «со средних нагрузок на процессор» на «средние нагрузки на систему». С тех пор учитываются задачи в непрерываемом состоянии, так что средние нагрузки отражают потребность не только в процессорных, но и в дисковых ресурсах. Обновлённые метрики подсчитывают количество работающих и ожидающих работы процессов (ожидающих освобождения процессора, дисков и снятия непрерываемых блокировок). Они выводятся в виде трёх экспоненциально затухающих скользящих сумм, в уравнениях которых используются константы в 1, 5 и 15 минут. Эти три значения позволяют видеть динамику нагрузки, а самое большое из них может использоваться для относительного сравнения с ними самими.
С тех пор в ядре Linux всё активнее использовалось непрерываемое состояние, и сегодня оно включает в себя примитивы непрерываемой блокировки. Если считать среднее значение нагрузки мерой потребности в ресурсах в виде выполняемых и ожидающих потоков (а не просто потоков, которым нужны аппаратные ресурсы), то эта метрика уже работает так, как нам нужно.
Я откопал патч, с которым было внесено это изменение в Linux в 1993-м — его было на удивление трудно найти, — содержащий исходное объяснение его автора. Также с помощью bcc/eBPF я замерил на современной Linux-системе трейсы стеков и длительность нахождения в непрерываемом состоянии, и отобразил это на внепроцессорном флем-графике. На нём отражено много примеров состояний непрерываемого сна, такой график можно генерировать, когда нужно объяснить необычно высокие средние значения нагрузки. Также я предложил вместо них использовать другие метрики, позволяющие глубже понять работу системы.
В заключение процитирую комментарий из топа kernel/sched/loadavg.c исходного кода Linux:
Hive OS. Установка, настройка, майнинг, команды, обновление. Полный туториал по системе.
Подробно разберем самую популярную систему для майнинга Hive OS. Hive OS представляет собой linux подобную операционную систему для майнинга на видеокартах и асиках. Выясним как правильно установить Hive OS, настроить систему Хайв ОС для стабильной работы, настроить и разогнать видеокарты, как сделать кошелек и полетные листы для запуска майнинга. Изучим команды и возможности обновления. И самое главное, разберем основные причины проблем и ошибок которые встречаются при майнинге на HiveOS.
Майнинг ETHW на Binance Pool
Комиссия 0.2%. Форк эфира. Ежедневные выплаты. Нет комиссий за перевод. Запуск!
БАЗОВЫЙ УРОВЕНЬ, ДЛЯ НОВИЧКОВ
Видео версия гайда по Hive OS
Регистрация в Hive OS
Hive OS промокод на 10$ при регистрации — InsidePC
В первую очередь нужно зарегистрироваться в HiveOS на официальном сайте. По данной ссылке с промо кодом «InsidePC», вы получите 10$ на счет, с которого сможете оплачивать систему. Регистрация в Hive OS ничем не отличает от регистрации в той же Rave OS, о которой мы писали в прошлой статье.
Когда вы попадете на сайт, нажмите на кнопку Sign In.
Регистрация в Hive OS
Если у вас есть промо код, нажмите Have a promo code?, нажмите и введите промо код InsidePC и получите 10$ на счет.
225$ для беженцев из Украины в ЕС!
Binance дарит 225$ для беженцев из Украины в странах ЕС + карта Binance VISA!
Промо код для получения 10$
После регистрации и входа в Hive OS, вы увидите веб интерфейс панели управления.
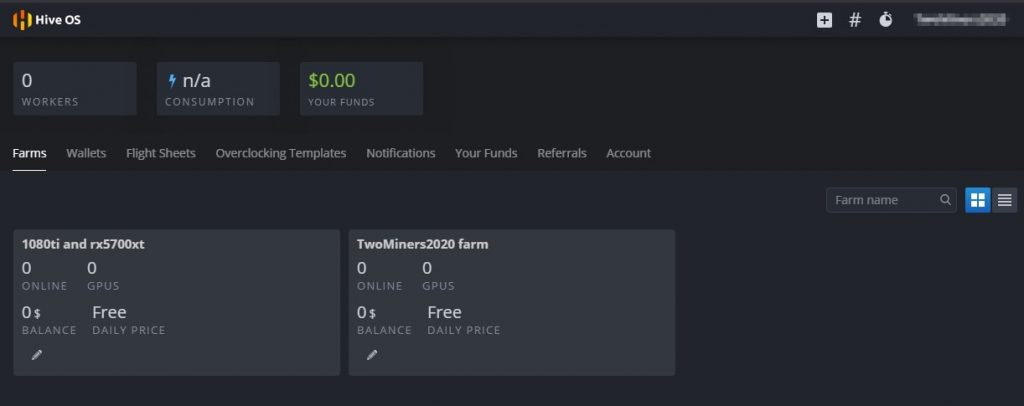
Панель управления Hive OS.
- Farms (Фермы) — ваши ферм.
- Wallets (Кошельки) — кошельки.
- Flight Sheets (Полетные листы) — полетные листы.
- Overclocking Templates (Шаблоны разгона) — шаблоны разгона.
- Notification (Уведомления) — уведомления.
- Your Funds (Ваши средства) — финансовые ведомости.
- Referrals (Рефералы) — рефералы.
- Account (Аккаунт) — аккаунт.
Как изменить язык системы
Рекомендуем использовать все профессиональные системы и сервисы на английском языке. Но если с английским совсем плохо, вы можете переключить на русский интерфейс. Для этого перейдите Аккаунты — Язык (язык будет сразу первой строчкой в настройках аккаунта). Хайв ОС на русский переведен качественно и профессионально.
Системные требования для Hive OS
Минимальные системные требования:
- Intel® Core™ 2 или лучше / AMD am2+ или лучше
- 4 ГБ ОЗУ*
- 4 ГБ носитель (HDD / SSD / M2 / USB
- Для добычи ETH (курс эфир) на RX Vega 56, RX Vega 64, Radeon VII, RX 5700 потребуется 6 ГБ оперативной памяти
Рекомендованные системные требования:
- Intel® Core™ i3-3220 3,3 ГГц / AMD FX-6300 3,5 ГГц
- 8 ГБ ОЗУ
- 8 ГБ SSD-накопитель
Настройки биос (bios) для материнской платы под Hive OS
- Настройте PCIe Link Speed на GEN2
- Отключите Internal Graphics (если это не нужно вам для монитора)
- Включите Above 4G Decoding
- Выключите CSM Support
- Убедитесь, что приоритет загрузки настроен правильно — устройство хранения, содержащее Hive, должно быть на первом месте
- (Опционально) Restore AC Power Loss (Power On)
Для ASUS B250 Mining Expert, PCIe Link Speed должна быть настроена в двух разных местах
- Advanced\PCH Configuration\PCI Express Configuration -> PCIe Speed -> Gen 2
- Advanced\System Agent (SA) Configuration\PEG Port Configuration -> PCIEX16_1 Link Speed -> Gen 2
И еще несколько рекомендаций касательно B250:
Майнинг Bitcoin на Binance Pool
Комиссия 0.2%. Нет комиссий внутри биржи. Ежедневные выплаты. Начать майнить!
- Некоторые пользователи сообщают о лучшей совместимости с Gen 1 вместо Gen 2 на более крупных ригах
- Некоторые пользователи сообщают об улучшенной стабильности при пустом слоте x16_1
- Обновленный bios может помочь решить множество проблем с платой
Скачиваем образ Hive OS для записи
Для скачивания образа HiveOS, используйте только официальный сайт. Ссылка на скачивания с официального сайта. Hive os скачать нужно обязательно по ней. Образ скачивается в ZIP архиве. Hive OS скачивайте только с официального сайта. Название образа будет примерно таким — hiveos-0.6-190-stable@210108.img.xz. Образ весит около 1,3 Gb.
Прежде чем записать образ Хайв ОС, разархивируйте его. Разархивированный образ для записи должен быть с расширением .img. Скачать hive os не должно составить для вас труда.
Установка образа Hive OS на SSD, HDD, M.2 или флешку
Структура фермы в системе Hive OS
Для понимания правильной настройки ваших ферм в системе Hive OS, объясним иерархию объектов в ферме.
Ферма (Farms) — представьте это как объект, например гараж или комната в которой размещены ваши воркеры или риги (до ригов или воркеров мы еще дойдем). Благодаря объединению ригов в фермы, вы можете разделять их по геолокации, например если у вас риги в разных гаражах, офисах, квартирах, комнатах. Это больше нужно для тех, у кого много ферм и ригов.
Hive os farm позволяют настривать фермы и локации.
Воркер (Workers) — это непосредственно ваш риг. Т.е. материнская плата с процессором, блоком питания и видеокартами. В обычной жизни, это и называют фермой. Как собрать майнинг ферму, читайте на сайте.
До 100$ при регистрации от Binance!
Забери приветственный бонус при регистрации на Binance прямо сейчас!
Нас интересует вкладка Фермы. Справа вверху нажимаем + и добавляем новую ферму.
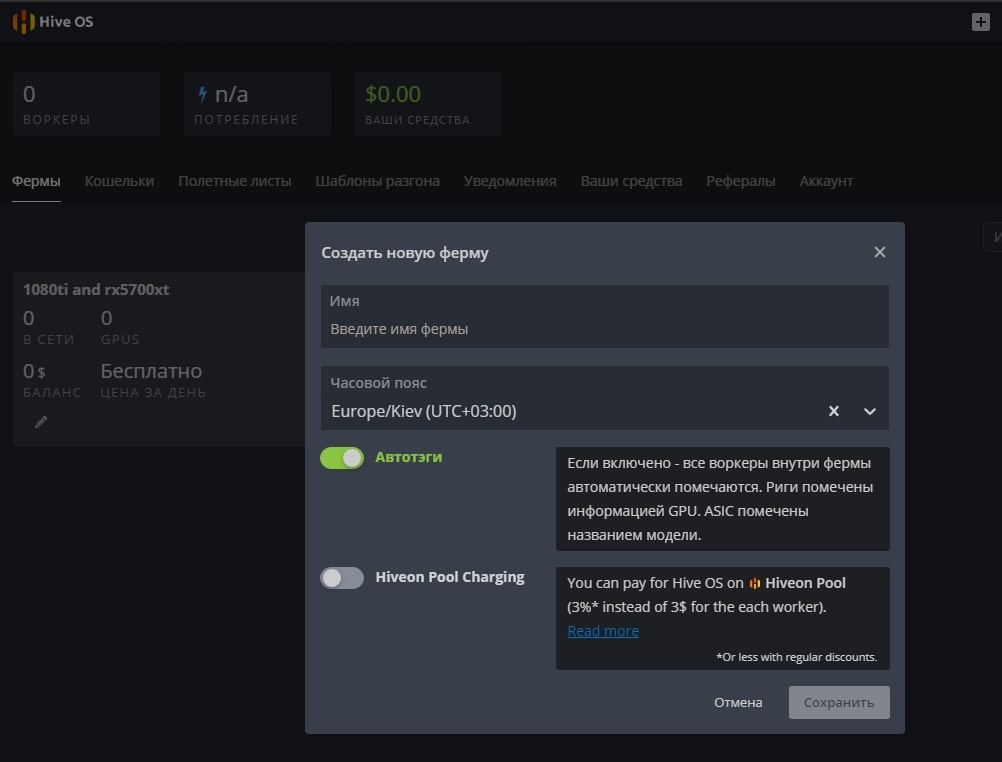
Создание новой фермы в Hive OS
- Имя — имя фермы.
- Часовой пояс — часовой пояс. Указывайте тот часовой пояс где находится ферма, это необходимо для отображения правильных временных кодов.
- Автотэги — полезная вещь, если у вас много ферм и много ригов. Автоматически помечает тэгами GPU и ASIC.
- Hiveon Pool Charging — данная опция позволят вам не платить за фермы 3$ в месяц, а оплачивать процент с пула. Мы не рекомендуем использовать Hiveon Pool, он не плохой, просто есть гораздо лучше пулы для майнинга эфира. Например Binance.
После создания фермы, вас перебросит на вкладку воркер. Справа вверху будет иконка «+» через которую вы создаете новый воркер.
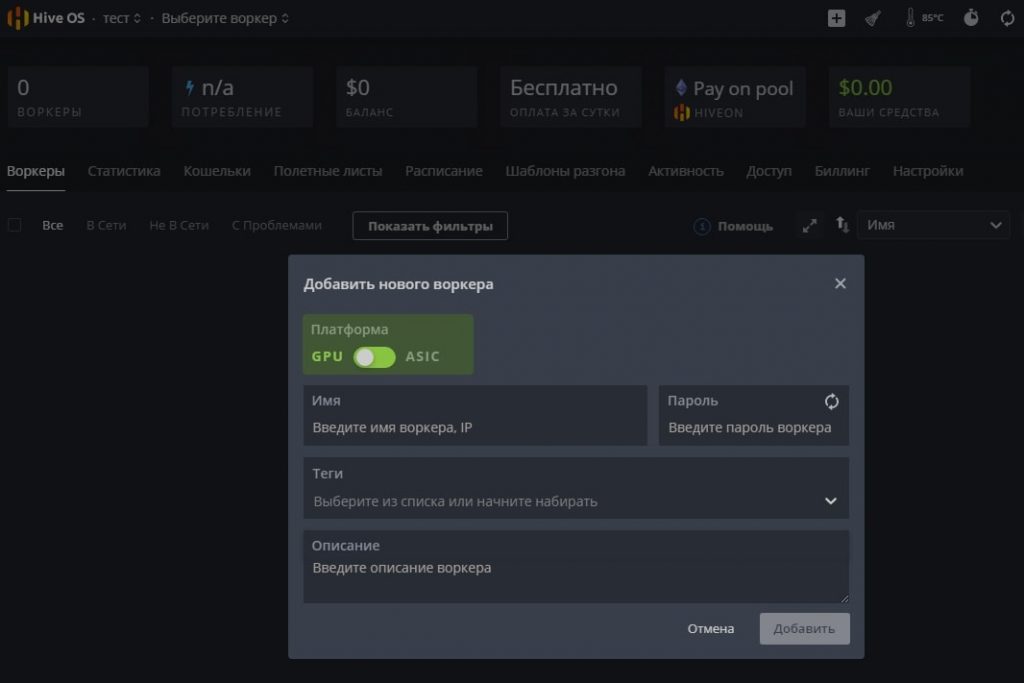
Создание воркера в HiveOS
- Платформа — выбираете GPU если у вас видеокарты, или ASIC если асики.
- Имя — имя воркера.
- Пароль — пароль воркера, для предоставления доступа.
- Теги — можете задать теги для удобства.
- Описание — описание воркера для себя.
После нажатие на кнопку «Добавить», вы попадаете в настройки рига или воркера.
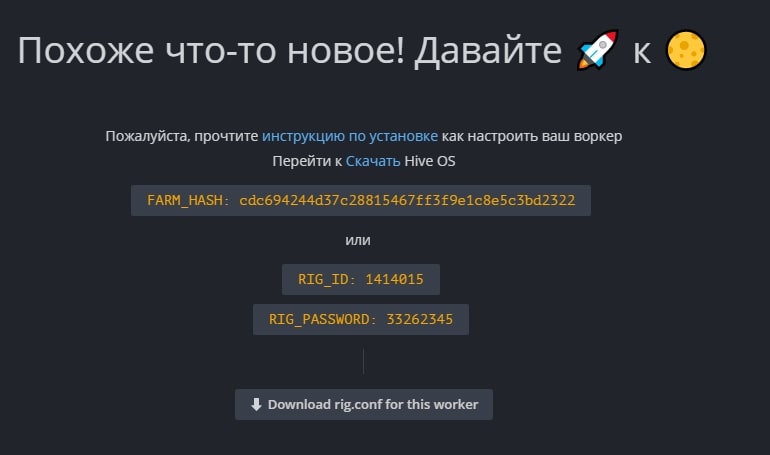
FARM_HASH and rig.conf
Тут нам нужен FARM_HASH. Это код который нужно будет вставить в образ Hive OS после записи этого образа. Либо вы можете в этом окне сказать rig.conf с уже прописанным FARM_HASH и скопировать в систему после создания образа. Мы рассмотрим оба варианта в Хайв ОС.
Устанавливаем образ Hive OS
Для записи образа Hive OS, проще всего воспользоваться программой HDD Raw Copy Tool. Мы покажем процесс установки на ней, но вы можете воспользоваться программой Etcher, она более современная.
Запускаем HDD Raw Copy Tool и в поле File выбираем образ Hive OS (Please select SOURCE).
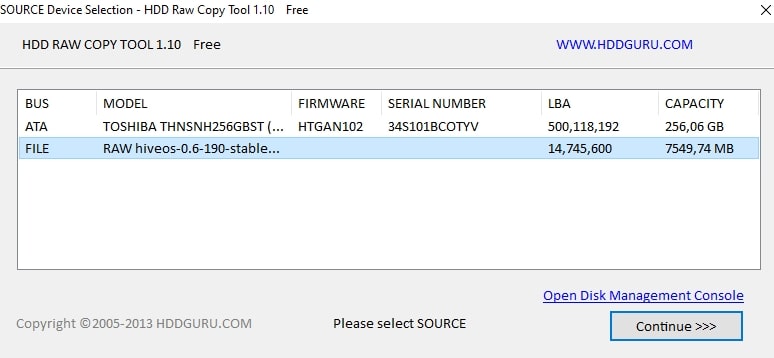
HDD Raw Copy Tool для записи Hive OS
Нажимаем Continue и выбираем диск или флешку на которую будем записывать образ в поле ATA (Please select TARGET).
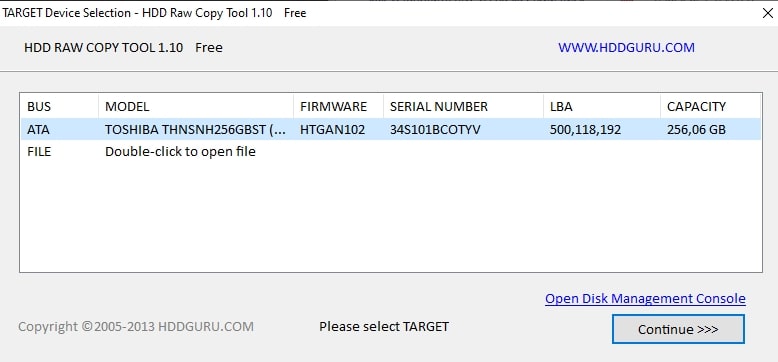
HDD Raw Copy Tool для записи Hive OS
Нажимаем Сontinue и подтверждаем запись.
После записи у вас появиться еще одни жесткий диск с файлами и именем Hive OS.
Вам нужно будет зайти в него и скопировать туда файл rig.conf, который вы скачали на предыдущем шаге. Либо найти там файл rig-config-example.txt и вставить в него FARM_HASH с воркера в поле FARM_HASH и сохранить этот файл с именем rig.conf.
После этого, нужно будет подключить образ к материнской плате фермы. К этому моменту вы уже должны были настроить материнскую плату фермы, ссылки выше на статьи и собрать и подключить ферму.
Запуск майнинга на Hive OS
Для запуска майнинга нужно помимо уже сделанного, создать кошелек и полетный лист.
Создание кошелька в Hive OS (куда мы будем майнить)
Создаем кошелек в Hive OS. В web интерфейсе переходим во вкладку «Кошельки» и нажимаем кнопку «Добавить кошелек». Лучше всего создавать разные кошельки для разных монет, особенно, если вы планируете майнить различные монеты и переключаться между ними. При выборе монеты в Полетных листах, выбор кошельков будет ограничен этой монетой.
Учитесь и зарабатывайте. +5$ сразу!
Проходите курсы и получите криптовалюту. Binance дает 5$ сразу за верификацию!
Создания полетного листа
Полетный лист позволяет переключаться мгновенно между кошелками, пулами, монетами. Это по сути файлы конфигурации вашего воркера.
Для создания полетного листа в Hive OS переходим во вкладку «Полетные листы (Flight Sheets)».
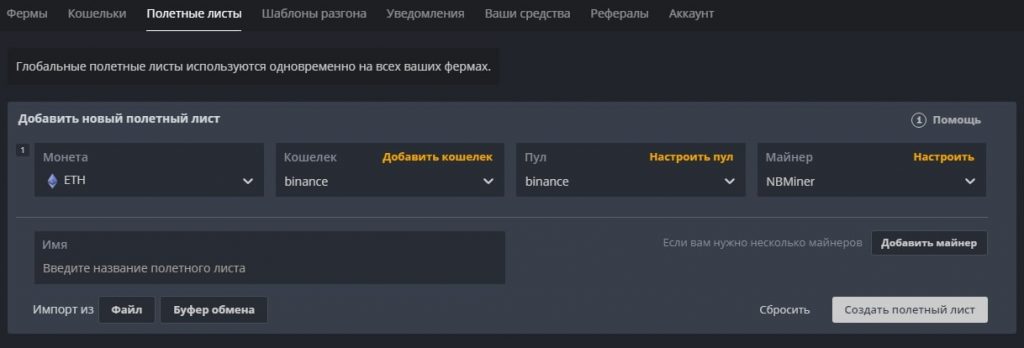
Создание полетного листа в Hive OS
- Монета — выбираем монету. В зависимости от выбранной монеты, будут доступны только кошелки для этой монеты.
- Кошелек — выбираем кошелек который мы создали ранее.
- Пул — выбираем пул на который будем майнить. А так же сервера пула. Если вы выбрали несколько серверов, то воркер будет присоединятся в порядке очереди к каждому следующему если предыдущий перестал работать. Лучше выбрать 2-3 сервера.
- Майнер — выбираем майнер. Рекомендуем использовать NBMiner. При выборе майнера, будет манятся текст Nvidia, AMD или CPU. В зависимости от того с какими картами работает майнер, или процессорами.
- Имя — вводим имя полетного листа.
Запускаем майнинг на Hive OS
Мы сделали все необходимое для запуска майнинга. Выбираем нашу ферму, выбираем наш воркер. Когда вы будете в воркере и будете видеть кол-во карт, перейдите в «Полетные листы».
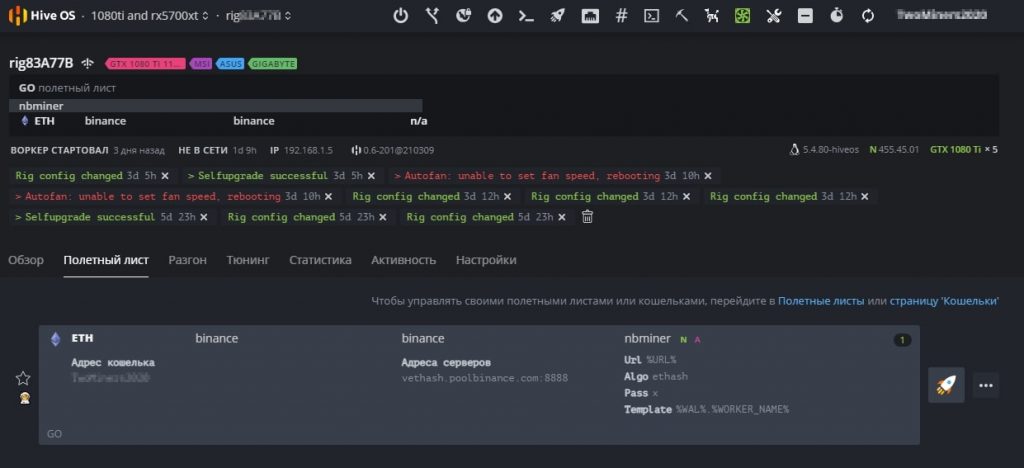
Запускаем майнинга на Hive OS
Нажимаем справа на ракете и запускаем майнинг.
Поздравляем, вы запустили майнинг на Hive OS. Подождите пару минут пока майнер запустить процесс майнинга.
Настройка аккаунта, фермы и воркера в Hive OS
Настройка аккаунта в Hive OS (Account Profile Settings)
Что бы попасть на страницу настроек аккаунта, с главной страницы Hive OS перейдите во вкладку Аккаунт (Account).
- Language (Язык) — изменения языка системы.
- Profile (Профиль) — логин, имя в системе и email.
- Notifications (Уведомления) — настройка уведомлений в Telegram или Discort.
- Password (Пароль) — изменение пароля.
- Two-factor Authentication (Двухфакторная аутентификация (2FA)) — подключение двухфакторной аутентификации. Дополнительный уровень безопасности.
- White List (Белый список) — белый список ip адресов. Не используйте это на динамическом IP адресе (если ваш интернет-провайдер меняет его или вы заходите через мобильную сеть)
- Authentication Tokens (Токены аутентификации) — Вы можете управлять своими персональными API токенами. Вы можете создать новый для своего стороннего приложения. Или удалить подозрительную сессию. Тут можете увидеть текущие сессии и закрыть их при необходимости. API документация тут.
- Bio (Биография) — тут можно ввести дополнительную информацию о вас: телефон, telegram, skype, информация о компании, часовой пояс.
- Advanced Settings (Расширенные настройки) — Delete account (Удалить аккаунт) — удаления аккаунта.
Настройка фермы в Hive OS
Что бы попасть на страницу настроек фермы в Хайв ОС, нужно выбрать нужную ферму, под каждую ферму свои настройки, и нажать на ссылку «Settings (Настройки)». Какие настройки фермы доступны в Hive OS?
- Name (Имя) — задаем имя фермы. Не на что не влияет.
- Farm Hash — Farm Hash используется для подключения воркера к ферме без предварительного создания в веб.Просто установите его в rig.conf перед первым запуском. Мы не расматриваем такой способ подключения, т.к. есть более удобные, описанные выше.
- ASIC configuration files (Файлы конфигурации ASIC) — Генератор файлов привязки ASIC. Настройка для асиков.
- Tags (Теги) — добавление своих тегов для маркирования воркеров.
- Timezone (Часовой пояс) — часовой пояс фермы.
- Notifications (Уведомления) — возможность настройки уведомлений для фермы. Т.е. они будут распространятся на все воркеры в ферме.
- Electricity price, $/kWh (Цена электроэнергии, $/кВт*ч) — Цена электроэнергии для точных подсчетов потребления. Вы можете установить валюту, добавив ее после пробела. Например: 5.47 RUB.
- Hardware power consumption, watts (Потребляемая мощность, Вт) — Значение по умолчанию для всех воркеров фермы. Может быть изменен для воркера отдельно.
- Power supply unit efficiency, % (КПД блока питания,%) — КПД блока питания для более точных подсчетов потребления. Значение по умолчанию для всех воркеров фермы. Может быть изменен для конкретного воркера.
- Advanced Settings (Расширенные настройки)
- Packages repository server mirror URL (Адрес зеркала сервера хранилища пакетов) — данная настройка позволяет указать локальные пакеты для обновления. Это позволит сохранить трафик и увеличить скорость обновления. Рекомендуется только для тех пользователей, которые понимают что это и точно знают зачем им это.
- Transfer farm (Передача фермы) — Передача фермы другому пользователю. Введите логин существующего пользователя, который будет новым владельцем фермы. Тут все должно быть понятно, передача фермы другому владельцу.
- Remove Farm (Удалить ферму) — Удаление фермы.
Настройка воркера в Hive OS
Для настройки воркера, нужно войти в нужный воркер и перейти во вкладку «Settings (Настройки)». Какие настройки воркера доступны в Hive OS?
- ID — уникальный идентификатор воркера. Так же в строчке с ID есть ссылка на готовый файл rig.conf.
- Farm hash — Farm hash вашего воркера который прописывается в файле rig.conf.
- Name (Имя) — имя воркера.
- Description (Описание) — описание воркера.
- Tags (Теги) — тэги для удобства сортировки видеокарт в воркере по типам памяти, моделям и т.д.
- Password (Пароль) — пароль воркера.
- Resend all configs (Переслать все настройки) — выгрузка настроек воркета для импорта в другую ферму.
- Cards/Boards Quantity (Количество карт/плат) — данный параметр увеличивается автоматически. Но можно его менять и вручную.
- GUI on boot (Отключить GUI при загрузке) — не запускать Х-сервер, только консоль, для Nvidia не будет разгона.
- Maintenance mode (Режим технического обслуживания) — включить режим обслуживания (не запускать майнер и сторожевой таймер при загрузке)
- Push interval (Интервал сброса данных) — Интервал в секундах между отправкой статистики на сервер. По умолчанию 10 секунд. Обратите внимание, что конфиги и команды будут обрабатываться воркеров с одинаковым интервалом.
- Power cycle — когда эта опция включена, все перезагрузки будут выполняться как выключить и включить через 30 секунд.
- DoH — DNS поверх HTTPS (DoH) — протокол для выполнения разрешения DNS по протоколу HTTPS. Использование DoH повышает конфиденциальность и безопасность пользователей путём предотвращения перехвата и манипулирования данными DNS.
- Miner delay (Задержка старта майнера) — задержка в секундах до запуска майнера при включении воркера.
- Hardware power consumption, watts (Потребляемая мощность, Вт) — вы можете установить энергопотребление «тушки» для более точного расчета энергопотребления.
- Power supply unit efficiency, % (КПД блока питания,%) — вы можете установить КПД блока питания для более точного расчета потребляемой мощности.
- Mirror Select (Выбор зеркала) — если у вас возникли проблемы с подключением к Hive сервера от вашего воркера и часто возникают ложные события не в сети / в сети, вы можете попробовать выбрать другой URL-адрес для подключения к серверу. Иногда возникает проблема с брандмауэром (ваш собственный или ISP) и смена порта может помочь.
- VPN — подключение VPN.
- Advanced Settings (Расширенные настройки)
- Transfer Worker (Перенос воркера) — перенести воркера на другую ферму. Кошелек не переносится с воркером. Пожалуйста, примените кошелек с другой фермы после того как перемещение будет завершено.
- Worker Activation/Deactivation (Активация воркера) — активация и деактивация воркера.
- Remove Worker (Удалить воркера) — удаление воркера.
Подключение и настройка Binance Pool через Hive OS
Подключение и настройка Binance Pool через Hive OS подробно описана в статье по Binance Pool. Переходите и изучайте.
Разгон видеокарт в Hive OS
Разгон видеокарт от NVIDIA
Шаг 1 — Заходим в ферму. Во вкладке Farms(Фермы), выбираем нужную ферму.

Шаг 2 — Заходим на нужный риг. Выбираем риг в котором стоят карты которые мы будем разгонять.

Workers в Hive OS
Шаг 3 — выбираем нужную карту, все карты, определенные карты. Выбираем нужную карту и нажимаем на значок спидометра. Можно выбрать этот значок напротив конкретной карты, либо выбрать значок спидометра с надписью ALL. Тут задаются настройки разгона для всех карт Nvidia или AMD. Если у вас несколько одинаковых карт в риге, можно применить разгон сразу ко всем картам. Так же можно разогнать только определенные карты, об этом ниже.
alt=»Разгон RTX 3070 в HiveOS» width=»1024″ height=»80″ />Разгон RTX 3070 в HiveOS
Шаг 4 — Устанавливаем параметры разгона. Окно настроек для видеокарт от AMD отличается от карт для NVIDIA и имеет свои нюансы:
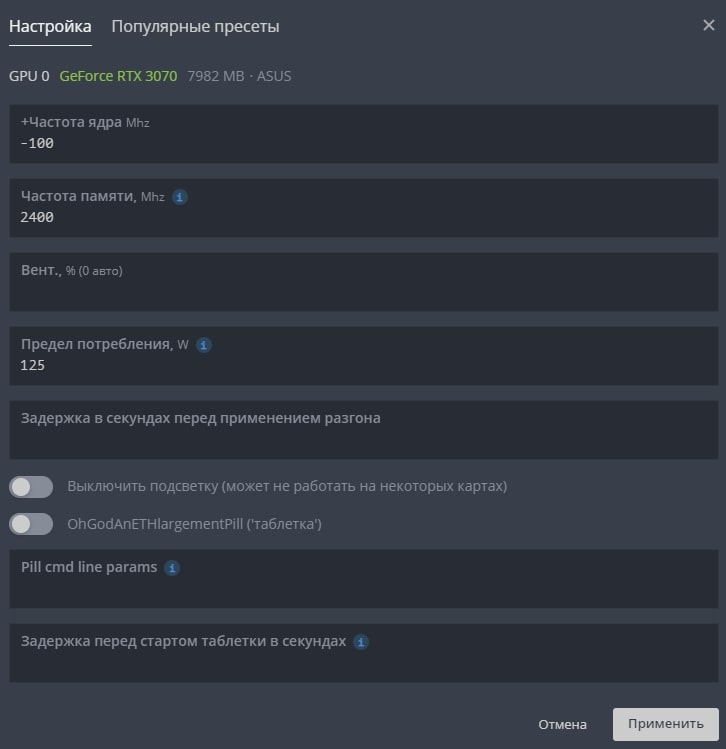 Оптимальный разгон и настройки RTX 3070 в Hive OS
Оптимальный разгон и настройки RTX 3070 в Hive OS
- В поле +Core Clock Mhz (+Частота ядра Mhz) — указываем частоту в Mhz которую вы добавляете или снижаете от базовой.
- В поле Memory Clock, Mhz (Частота памяти, Mhz) — указываем значение частоты видео памяти. Частота видео памяти указывается умноженная на 2. Т.е. если вам нужно увеличить частоту на 1000 MHz, вбиваете 2000 Mhz. Это особенности разгона на Hive OS и Rave OS.
- В поле Вент., % (0 авто) — частота вращения вентиляторов. Оставляете 0 если у вас стоит Auto Fan.
- Предел потребления, W — указываете предел потребления карты в ваттах.
- Задержка в секундах перед применением разгона — указываете в секундах задержку начала разгона после того, как карта запустилась. Иногда это помогает от отвала видеокарты.
- Выключить подсветку (может не работать на некоторых картах) — очень редко работает.
- OhGodAnETHlargementPill — включает так называемую таблетку (Pill), используется только для карт серии gtx 10 80.
- Pill cmd line params — можно указать ревизию карт для которых для запуска таблетки.
- Задержка перед стартом таблетки в секундах — задержка применения таблетки от времени запуска видеокарты.
Популярные пресеты
В этом разделе, можно выбрать пресет или шаблона разгона который используют другие пользователи Hive OS для таких же карт как у вас.
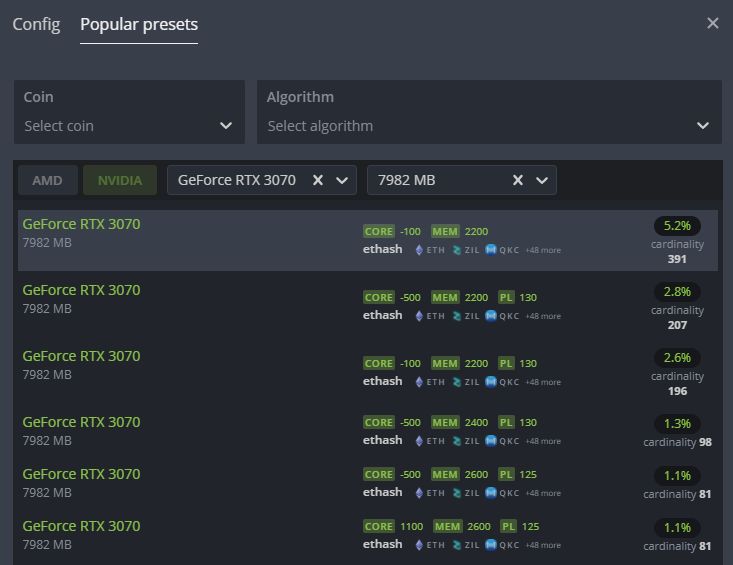 Popular Presets
Popular Presets
Нажимаете на нужный пересет разгона и он применится к вашей карте.
Разгон нескольких карт из рига
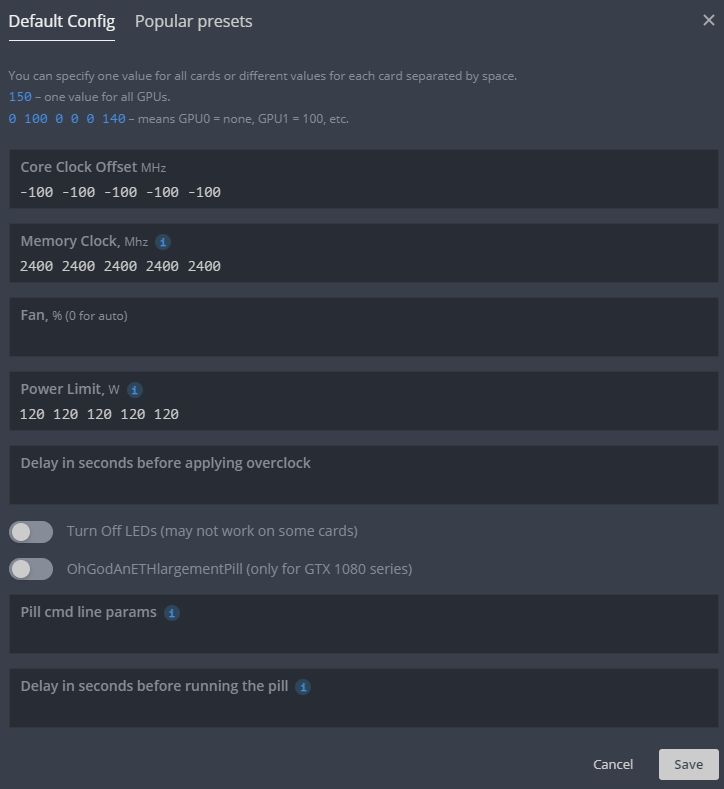 Разгон нескольких карт из рига
Разгон нескольких карт из рига
Заходите в настройки разгона всех карт, и по отдельности указываете значения разгона для каждой отдельной карты. Порядок от GPU 0 до GPU N…
Разгон видеокарт от AMD в Хайв ОС
Для карт от AMD есть гораздо больше настроек для разгона, вы можете указывать не только лимит потребления, но и вольтаж на память, на чип и другие, в зависимости от поколения графического чипа.
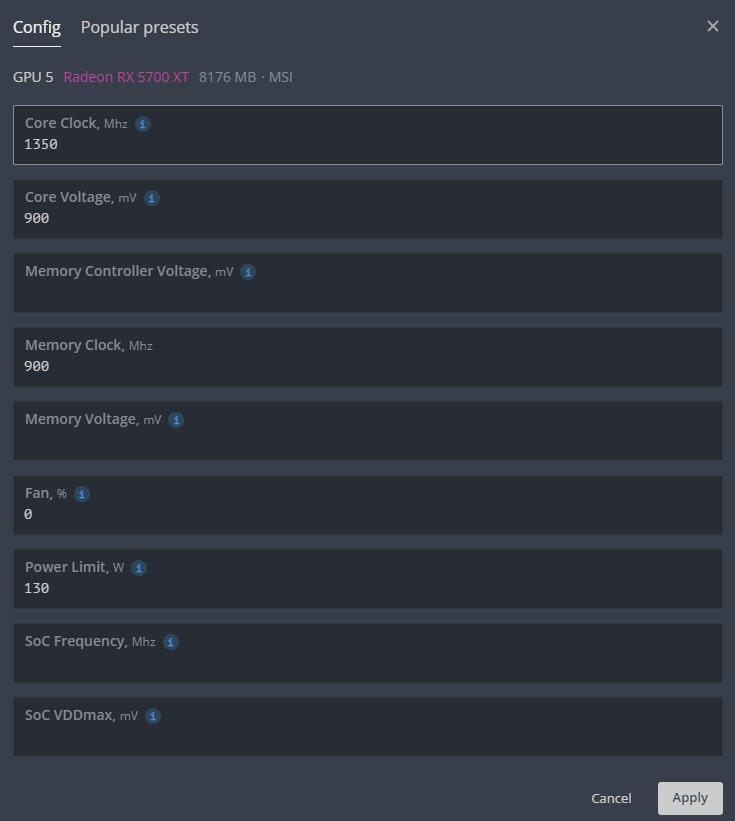
Разгон RX 5700 XT в Hive OS
- В поле Core Clock offset, Mhz — указываем частоту в Mhz которую вы добавляете или снижаете от базовой.
- В поле Core voltage, mV — указываем значения потребления графического чипа в милливольтах.
- В поле Memory Clock offset, Mhz — указываем значение частоты видео памяти. Частота видео памяти указывается умноженная на 2. Т.е. если вам нужно увеличить частоту на 1000 MHz, вбиваете 2000 Mhz. Как и для карт NVIDIA.
- В поле Memory voltage, mV — указываем значения потребления видеопамяти в милливольтах.
- В поле Power Limit — указываете предел потребления карты в ваттах.
Polular presets — работают так же как и на картах Nvidia. Выбираете нужный шаблон и применяете его.
Как включить уведомления в Hive OS на Telegram или Discord
Вы можете настроить уведомления по различным событиям в системе и получать их на свой telegram или discord. Какие уведомления можно получать на Telegram и Discord с Hive OS:
- Воркер в сети
- Воркер не в сети
- Воркер загрузился
- Сообщения об ошибках
- Предупреждающие сообщения
- Информационные сообщения
- Выполненные без ошибок
- GPU Temp >= Red Temp + 3°
- Почасовой отчет
- Скорость вентилятора >= Порог + 5%
- Коэф. подтв. шар >= Порог — 5%
- Средняя нагрузка (15 мин) >= Порог + 1
- Потеря GPU/платы
- GPU MEM TEMP >= Red MEM TEMP + 3°
- CPU TEMP >= Red CPU TEMP + 3°
- ASIC Board TEMP >= Red ASIC TEMP + 3°
Список уведомлений очень большой. Что в целом позволит вам во время узнавать и реагировать на любые события на ферме.
Как настроить эти уведомления?
Переходите на Фермы и выбираете нужный Воркер, там ищем вкладку — Настройки. Спускаемся к Уведомлениям.
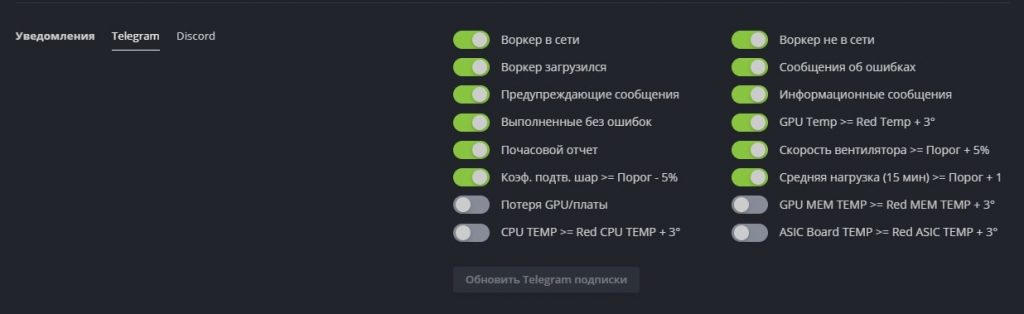 Уведомления на telegram или discord в hive os
Уведомления на telegram или discord в hive os
Для настройки уведомлений, перейдите по ссылке на Hive OS Bot, получите код в боте и на email. Введите их в системе и подписка будет оформлена.
 Уведомления в Telegram в Hive OS
Уведомления в Telegram в Hive OS
Обновление системы Hive OS и обновление драйверов для видеокарт
Какая версия Hive OS установлена?
Для обновление Hive OS, обратите внимание, не Ubuntu на базе которой написана Hive OS, а именно Hive OS, необходимо зайти в ваш воркер.
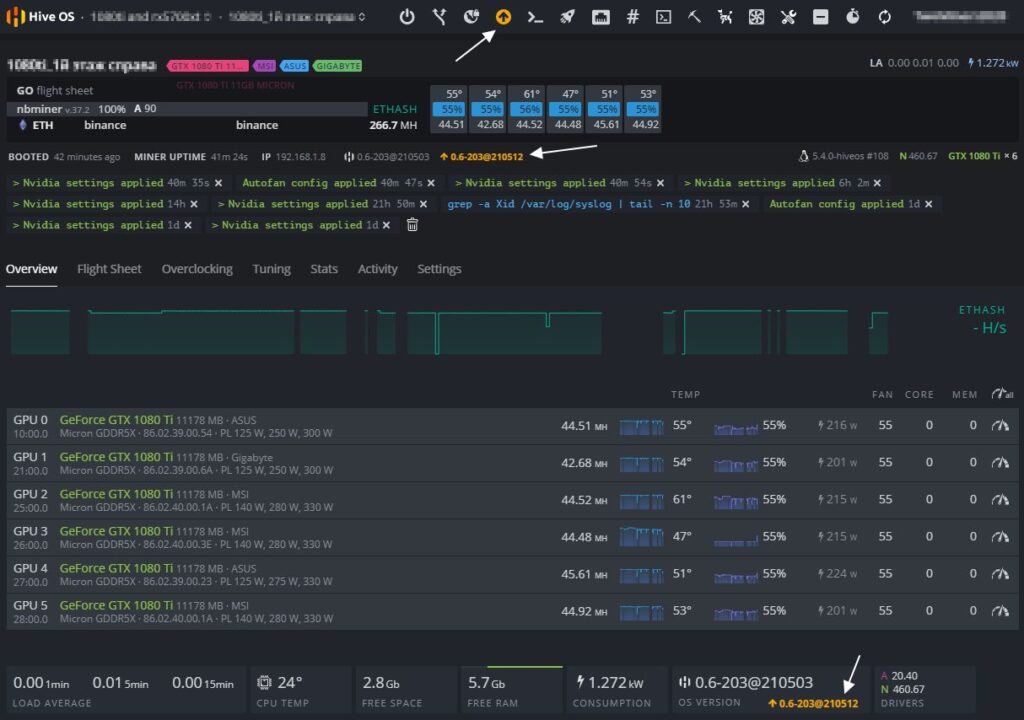
Обновление Hive OS
Желтым цветом вы увидите последнюю версию системы, а рядом белым цветом будет обозначена текущая версия Hive OS. В моем случае, стоит 0.6-203@210503, а последняя версия на данный момент 0.6-203@210512.
Обновление Hive OS до последней версии (Upgrade)
Для обновления Hive OS до последней версии, нажмите на желтую иконку («Upgrade or Downgrade»).
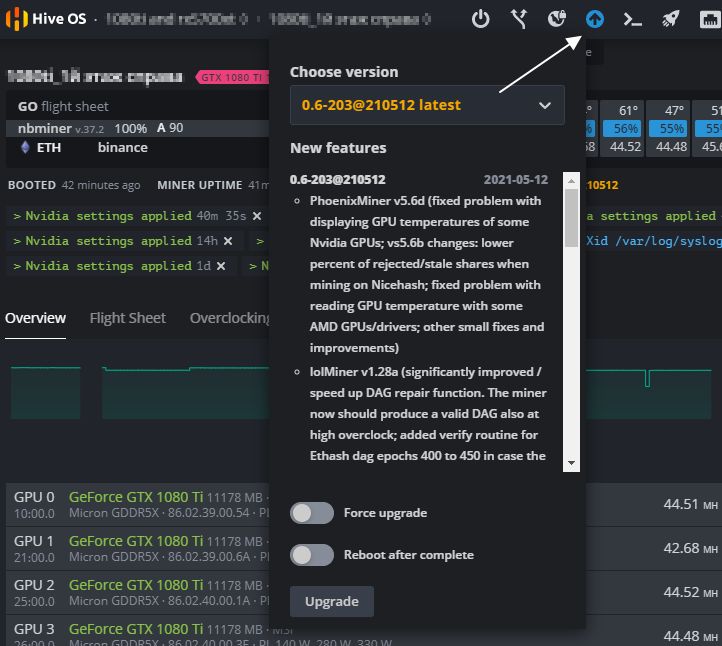
Обновление Hive OS
Во всплывающем окне, вы можете выбрать версию на которую вы можете обновиться, а также почитать основные изменения в новой версии. Выбрав версию, нажимаете серую кнопку внизу «Upgrade». После нажатия кнопки, нужно будет дождаться процесса обновления. Обычно это занимает не более 2х минут.
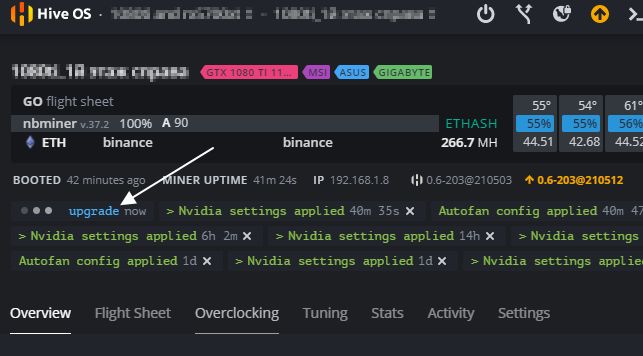
Кнопка Reboot after complete — обновит воркер после успешного обновления Hive OS.
Как откатиться на предыдущие версии Hive OS (Downgrade)
В той же иконке (Upgrade or Downgrade), выбираем предыдущие версии на которые мы можем сделать откат.
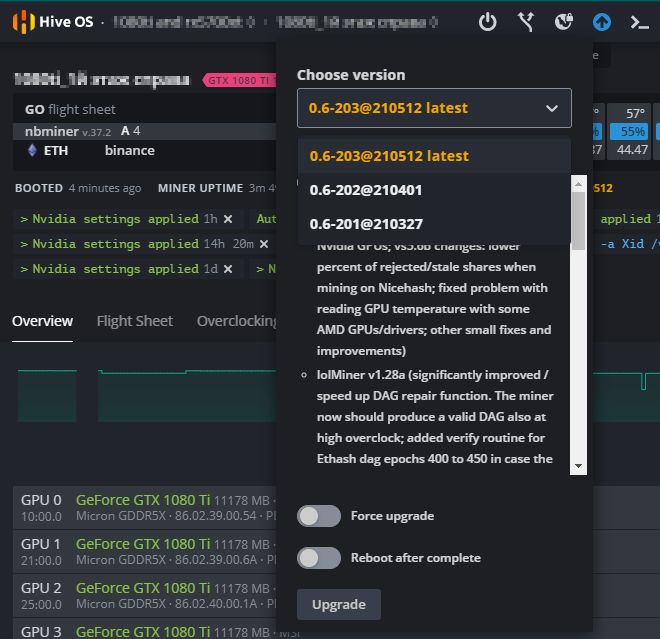
Белым цветом написаны предыдущие версии системы на которые вы можете откатится. Выбираете нужную и нажимаете Upgrade. Все очень просто.
Как обновить драйвера для карт NVIDIA
Обновление драйверов в Hive OS можно сделать только для карт Nvidia, для карт AMD драйвера обновляются вместе с дистрибутивом сомой системы. Т.е. при обновлении версии Hive OS. Прежде чем обновлять драйвера, посмотрите какие драйвера установлены на вашем риге.
Для этого перейдите в Фермы — Воркеры — Выберите нужный воркер и нажмите на него. Попав в воркер, можно посмотреть версию драйверов.
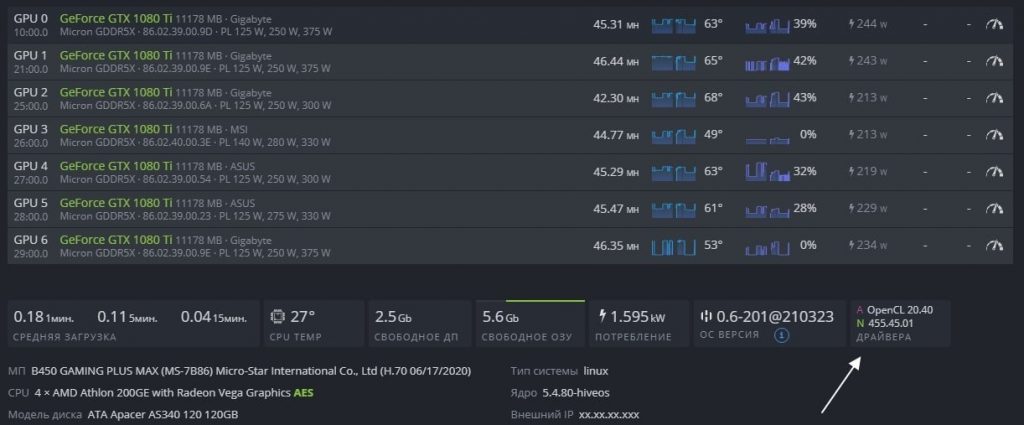
Версия драйвера в HiveOS
В нашем случае версия драйверов — 455.45.01.
Следующий шаг, это узнать последнюю актуальную версия драйвера для карт Nvidia. Нужно запустить Shell.
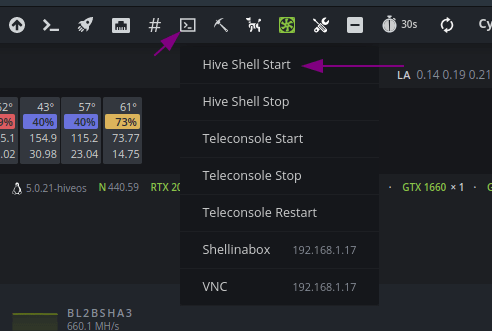
Находясь в воркере, выбираем «Удаленный доступ» и «Hive Shell Start».
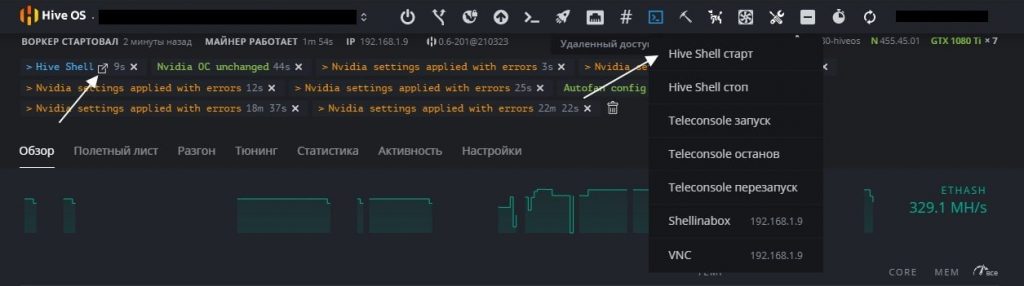
Hive Shell старт
После запуска Hive Shell, открываем окно Hive Shell.
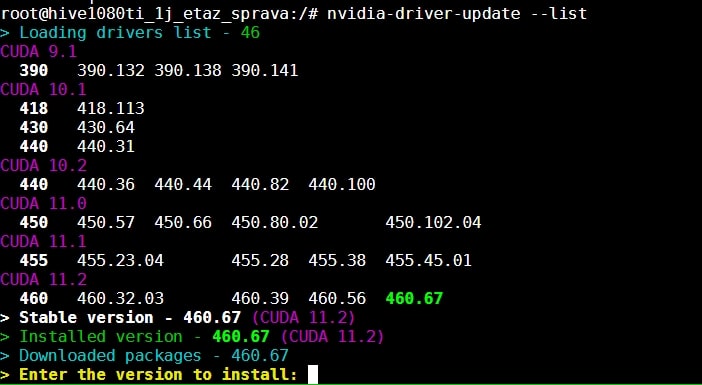
Вводим команду nvidia-driver-update —list.
Вы увидите список доступных драйверов для установки. Узнаете версию Cuda для вашего устройства.
Для обновления драйвера введите команду upt update.
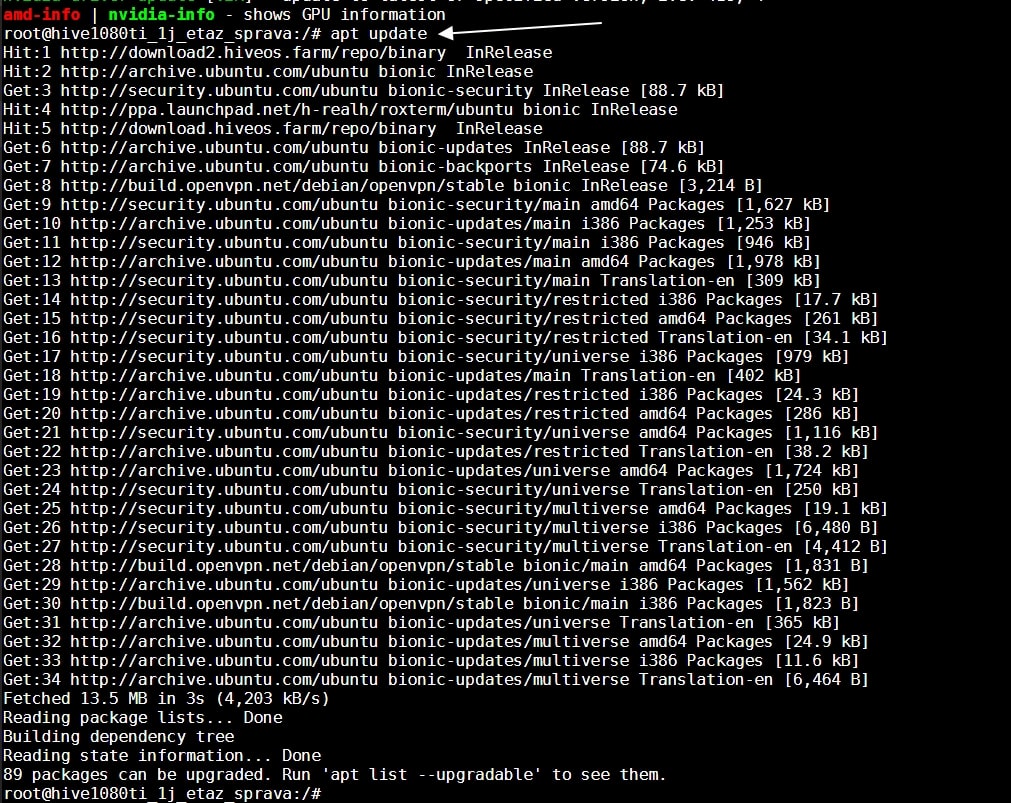
После выполнения этой команды, вводим команду на обновление драйвера.
Если есть более новая версия драйвера, вводите команду nvidia-driver-update 455.38 (указываете версию драйвера), либо просто вбиваете команду nvidia-driver-update и он будет ставить самую последнюю актуальную версию.

Обновления займет пару минут, после успешного обновления драйверов на hive os для nvidia, вы должны увидеть следующее окно:
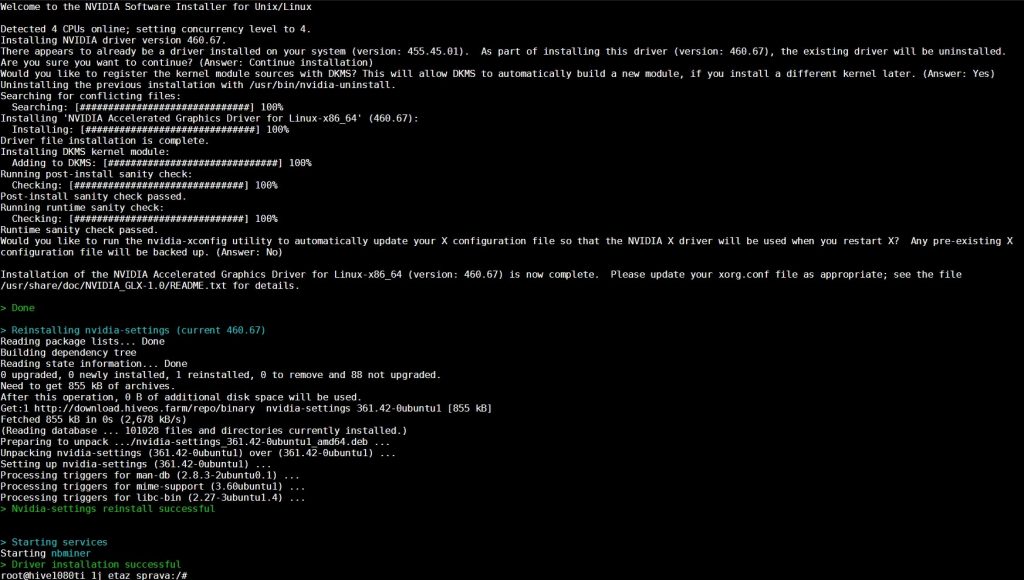
Nvidia settings reinstall seccessful
Все, обновление драйвера прошло успешно.
Driver installation successful
Как обновить драйвера для карт AMD в Hive OS
Драйвера для карт AMD обновляются вместе с обновлением образа Hive OS. Других варианты не рекомендуются.
Зомби режим в Hive OS
Шаг 1: Заходим в Flight Sheets (полетные листы) и создаем полетный лист. Монету выбираем ETH, прописываем свой кошелек (нужно предварительно его создать), пул, и майнер. Выбираем TeamRedMiner и нажимаем Настроить ( Setup Miner Config).
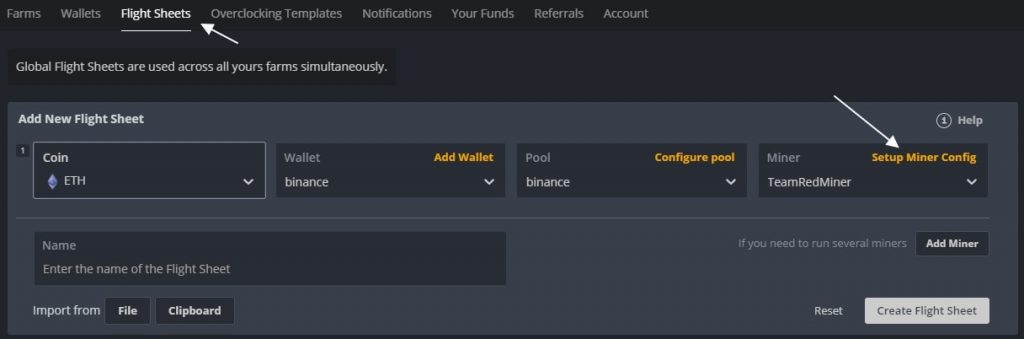
Создаем Flight Sheets (полетный лист) и выбираем майнер TeamRedMiner
В насройках майнера, находим поле Extra config arguments и вводим следующую команду — —eth_4g_max_alloc 4076.
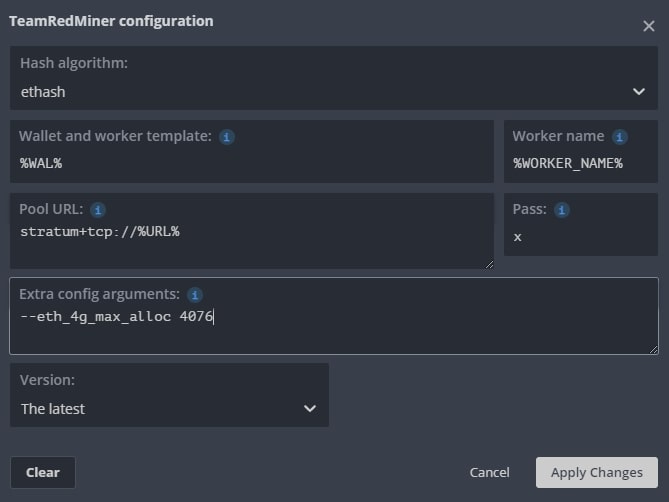
Эта команда указывает сколько видеопамяти в карте будет использоваться под DAG файл. Все что больше этого значения будет размещаться в оперативной памяти. Чем выше эта цифра, тем меньше будет падение хэшрейта в майнинге. У нас стоит 4076 mb. Это цифру вам нужно подобрать самим. Если на 4076 все работает стабильно, попробуйте поднять на 10 mb.
Нажимаем Apply Changes и сохраняем полетный лист. Полетный лист называем как то понятно, Zomby List или как то так.
Более подробнее про майнинг на картах с 4GB видеопамяти читайте в статье по майнингу на RX 480, RX 570, RX 580.
Проверка логов в Hive OS для поиска проблем и ошибок
В Hive OS есть несколько журналов с логами, которые вы можете анализировать для поиска проблем, ошибок или проверки работы. Вы можете посмотреть журнал майнера и журнал системы.
Как посмотреть лог майнера в Hive OS
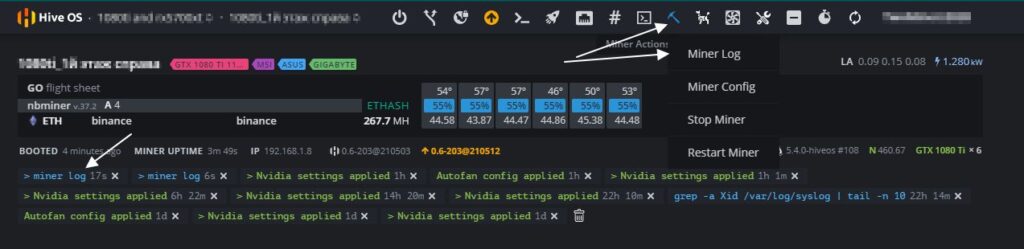 Miner Log
Miner Log
Ищем иконку под названием «Miner Actions» и выбираем раздел Miner Log. Вы увидите следующий лог из последних 100 строк работы майнера (это даже не лог, а просто экран майнера):
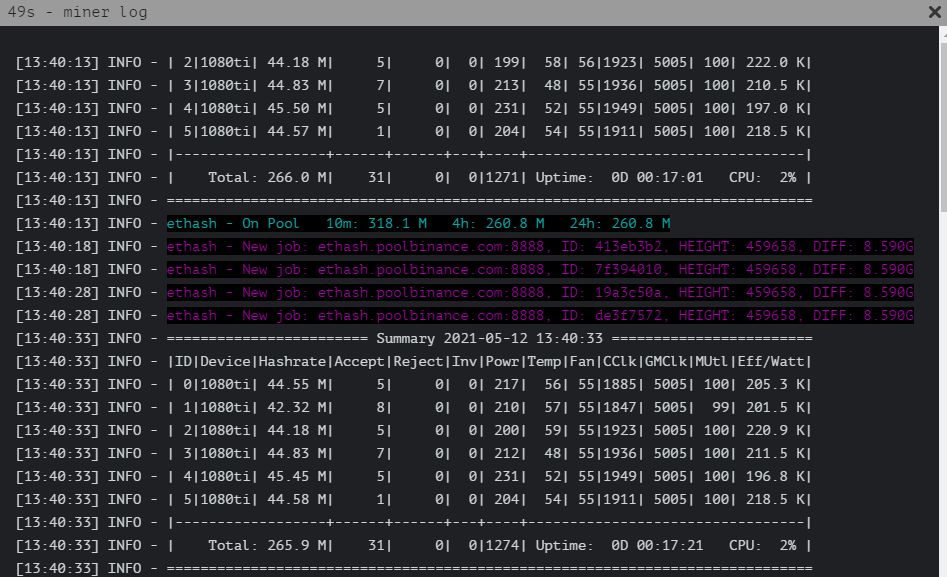 Miner Log
Miner Log
Настоящие файлы хранятся в /var/log/miner/xxxx/*.log. Как их увидеть?
Открываем «Remote Access» и выбираем Hive Shell Start.
После загрузки терминала, вы увидите иконку открытия терминала в новом окне:
Нажимаем на нее и переходим в терминал, который откроется в соседней вкладке.
У нас откроется терминал в котором мы прописываем команду «mc» и нажимаем Enter.
Переходим стрелками в папку /var/log/miner/xxxx/*.log. Где xxx — это название вашего майнера и внутри этой папки смотрим папку с логом. Для просмотра лога нажимаем F3. Для выхода из mc нажимаем F10.
Как посмотреть системный лог в Hive OS
Для доступа в главный системный журнал, вбейте в Hive Shell — less /var/log/syslog
Команды в Hive OS
Базовые команды
- agent-screen— показывает агент клиента Hive OS (чтобы выйти, нажмите Ctrl+A, D)
- firstrun -f— заново запросить ID рига и пароль
- mc— файловый менеджер, наподобие Norton Commander, но для Linux
- selfupgrade— обновление Hive OS через консоль, то же самое, что нажать кнопку в веб-интерфейсе
- sreboot— выполнить принудительную перезагрузку
- sreboot shutdown— выполнить принудительное отключение
Майнеры
- miner— открывает окно с запущенным майнером (чтобы выйти, нажмите Ctrl+A, D)
- miner start, miner stop— запускает или останавливает настроенный майнер
- miner log, miner config— лог / настройки майнера
Логи системы
- dmesg— показать системные сообщения, в основном, чтобы увидеть лог загрузки
- tail -n 100 /var/log/syslog— показать 100 последних строк из системного лога
Сеть
- ifconfig— показать интерфейсы сети
- iwconfig— показать беспроводные адаптеры
Горячие клавиши
Ctrl+C— остановить любую запущенную команду
Переключение между экранами майнеров, отсоединение от терминала:
- Ctrl+A, D— отсоединить от экрана (майнер или агент), чтобы оставить его работающим
- Ctrl+A, Space or Ctrl+A, 1,2,3— переключение между экранами, если у вас запущено несколько майнеров и т.д.
Продвинутые команды
Статус / Диагностика
- agent-screen log— показать логи разных частей (вы можете использовать log1 и log2) агента Hive
- hello— «поздороваться» с сервером: чтоб обновить IP адреса, настройки, и так далее (обычно выполняется при запуске)
- net-test— проверить и определить сетевое соединение
- timedatectl— показать время и дату настроек синхронизации
- top -b -n 1— показать список всех процессов
- wd status— показать статус и лог хешрейт-вотчдога
AMD
- amd-info— показать данные по картам AMD
- amdcovc— показать данные о питании карт AMD
- amdmeminfo— показать данные о памяти карт AMD
- wolfamdctrl -i 0 —show-voltage— показать таблицу напряжения для видеокарт AMD #0
Nvidia
- journalctl -p err | grep NVRM— показать последние ошибки видеокарт Nvidia
- nvidia-info— показать расширенные данные по картам Nvidia
- nvidia-driver-update— обновление драйверов Nvidia
- nvidia-driver-update 430— скачать и установить последний драйвер из серии 430.*
- nvidia-driver-update —nvs— переустановить только nvidia-settings
- nvidia-smi— показать данные по картам Nvidia
- nvtool —clocks— показать частоты ядра/памяти для всех видеокарт Nvidia
Оборудование
- gpu-fans-find— вращать вентиляторы GPU от первой до последней карты, чтобы упростить поиск необходимого GPU. Можно указать номер карты, тогда вентиляторы запустятся именно на ней. Если воркер запускается корректно, отследить какая карта какой шине соответствует довольно просто. Например, если карта GPU0 имеет шину 01:00.0, и её нужно найти, используйте команду gpu-fans-find 0. Эта команда на некоторое время раскрутит вентиляторы только на этой карте. И так далее по примеру.
- sensors— показать показания напряжения/температуры материнской платы и карты
- sreboot wakealarm 120— выключить блок питания и запустить через 120 секунд
- /hive/opt/opendev/watchdog-opendev power— эмуляция нажатия кнопки питания посредством OpenDev вотчдога
- /hive/opt/opendev/watchdog-opendev reset— эмуляция нажатия кнопки перезапуска посредством OpenDev вачдога
Апгрейд / Установка
- disk-expand -s— расширить раздел Linux, чтобы заполнить оставшееся на диске место
- hpkg list miners— список всех установленных майнеров
- hpkg remove miners— удалить все майнеры
- nvidia-driver-update —remove— удалить все загруженные пакеты драйверов Nvidia, кроме утсановленного на данный момент
- selfupgrade —force— принудительный апгрейд; это поможет в ситуации, когда selfupgrade сообщает, что версия Hive актуальна, но на самом деле это не так
Логи
- journalctl -u hive —no-pager— показать загрузочный лог Hive OS
- journalctl -u hivex —no-pager— показать лог X сервера (графический интерфейс)
- logs-on— записать все логи на диск, они сохранятся после перезагрузок
- logs-off— записать все логи в оперативную память, чтобы уменьшить износ USB-накопителя (по умолчанию)
- log=’/var/log/syslog’; gzip -c9 «$log» | base64 -w 0 | message file «$(basename «$log»)» payload— отправить файл /var/log/syslog на панель управления
Как запускать команды
Есть несколько способов запуска команд, прежде всего вам нужно зайти в нужный воркер:
- Выбрать пункт «Выполнить команду», и вбить необходимую команду.
- Выбрать пункт «Удаленный доступ», и выбрать Hive Shell Start.
Остались вопросы или что то не понятно?
Заходите на наш telegram канал и задавайте их напрямую автору. Помимо общения, публикуем то, чего нет на сайте. Будьте в курсе лучших возможностей заработка на криптовалюте!
Newsletter
Еженедельный отчет по криптопортфелю. Дайджест топовых новостей и возможностей в крипте. Подсвечиваем актуальные темы для заработка!
Владимир — CEO InsidePC. Более 10ти лет в интернет-маркетинге и IT индустрии, 4 года в трейдинге на NYSE, NASDAQ, более 3х лет исключительно в крипте. В фокусе трейдинг, инвестиции, ноды и майнинг. Держу руку на пульсе криптовалютной индустрии. Цель — развитие крипто индустрии в Украине.
Telegram
Load average hive os красным как исправить
здравствуйте как понизить лоад авэредж. вставлял карты по очереди, менял первую вставленую карту на другую, повышал напряжение до 900 на всех и все бес толку. пулл хайв, майнер тимрэд сейчас 1,9 но он постоянно скачет от 1,8 до 2,5 приблизительно,, я так понимаю что какая то из карт вешается? ну так я и разгон уменьшал и напругу повышал ничего
Последнее редактирование: 24 Фев 2021
вопрос — а на куя?
а не усе, снято))) 2 минуты на загрузку эт РИП)))
здравствуйте как понизить лоад авэредж. вставлял карты по очереди, менял первую вставленую карту на другую, повышал напряжение до 900 на всех и все бес толку. пулл хайв, майнер тимрэд сейчас 1,9 но он постоянно скачет от 1,8 до 2,5 приблизительно,, я так понимаю что какая то из карт вешается? ну так я и разгон уменьшал и напругу повышал ничего
Посмотреть вложение 172172
Хайв на ссд накати,у меня есть фермы с флешками а есть с ссд,на ссд проблем нету,можешь попробовать обычный жёсткий,но я хз не пробовал какая там скорость загрузки
Такая-же проблема. Собрал/разобрал риг и стал появлятся переодически LA. При подключении ещё одной карты в риг LA идет выше и выше пока карта не отвалится или риг целиком. Заменил райзер, риг и карта перестал отваливаться, но шестую карту повесить не могу.
ни на одном из ригов ЛА не был еще выше 40 секунд — и это считаю я, долго… а тут тема про 2 минуты…
флешка? или 486sx-40 проц?
Такая-же проблема. Собрал/разобрал риг и стал появлятся переодически LA. При подключении ещё одной карты в риг LA идет выше и выше пока карта не отвалится или риг целиком. Заменил райзер, риг и карта перестал отваливаться, но шестую карту повесить не могу.
Попробуйте ластиком потереть дорожки золотые на видеокартах а так же на концах райзера которые в мать вставляются и оперативку можно за одно,все с обоих сторон
Попробуйте ластиком потереть дорожки золотые на видеокартах а так же на концах райзера которые в мать вставляются и оперативку можно за одно,все с обоих сторон
Там в соседней теме пишут что рейв/хайв это круто.
Вы из одной секты или разные?
Такое чувство что никто не понимает что такое load average в линуксе. Это просто загрузка системы. Открой top, посмотри что грузит проц. Если ничего, вероятно, затык из-за io (файловой системы). Как уже сказали, посмотри выключены ли логи.
здравствуйте как понизить лоад авэредж. вставлял карты по очереди, менял первую вставленую карту на другую, повышал напряжение до 900 на всех и все бес толку. пулл хайв, майнер тимрэд сейчас 1,9 но он постоянно скачет от 1,8 до 2,5 приблизительно,, я так понимаю что какая то из карт вешается? ну так я и разгон уменьшал и напругу повышал ничего
Посмотреть вложение 172172
А ну покажи табличку тюнинга любой 570-й. Что там еще прописано.
1. Обнови до последней версии.
2. Снизь разгон нулевой карты. Инкорректов не должно быть совсем.
3. Замени флешку на SSD.
В случае «плохого» Load Average тебе сама ОС его подсветит красным.
А ну покажи табличку тюнинга любой 570-й. Что там еще прописано.
И еще amd -info скрин.
1. Обнови до последней версии.
2. Снизь разгон нулевой карты. Инкорректов не должно быть совсем.
3. Замени флешку на SSD
обновлен.инкорект нулевой не из за разгона у нее чипы перегреваются не удачная конструкция асуса) а насчет флешки я сам грешил попробую заменить но нет под рукой не ссд не флешки лишней ,если ты думаешь что вот проблема, то нет, я убирал эту карту из рига, не чего не изменилось, кстате не по теме карты асус стрикс идет с завода бе з прокладок причем три чипа даже не обдуваются кто нибудь их модернизировал?по ка спасает большой куллер на обратную сторону платы
А ну покажи табличку тюнинга любой 570-й. Что там еще прописано.
Попробуйте ластиком потереть дорожки золотые на видеокартах а так же на концах райзера которые в мать вставляются и оперативку можно за одно,все с обоих сторон
попробую тоже0 а вдруг
отключил закрузка просела но не на долго до 1,3 потом снова 2,9
Такое чувство что никто не понимает что такое load average в линуксе. Это просто загрузка системы. Открой top, посмотри что грузит проц. Если ничего, вероятно, затык из-за io (файловой системы). Как уже сказали, посмотри выключены ли логи.
что значит открой тоП?
Попробуй ничего не прописывать в даунвольт памяти. Никаких vddci и mvdd. И посмотри как будет с LA. В самом майнере никаких доп. комманд нет?
Последнее редактирование: 24 Фев 2021
вроде как бы и не грузит не чего спасибо кстате не знал про эту команду, что выходит? флэшка? 


Средние значения нагрузки (Load averages) — это критически важная для индустрии метрика. Многие компании тратят миллионы долларов, автоматически масштабируя облачные инстансы на основании этой и ряда других метрик. Но на Linux она окутана некой тайной. Отслеживание средней нагрузки на Linux — это задача, работающая в непрерываемом состоянии сна (uninterruptible sleep state). Почему? Я никогда не встречал объяснений. В этой статье я хочу разгадать эту тайну, и создать референс по средним значениям нагрузки для всех, кто пытается их интерпретировать.
Средние значения нагрузки в Linux — это «средние значения нагрузки системы», показывающие потребность в исполняемых потоках (задачах) в виде усреднённого количества исполняемых и ожидающих потоков. Это мера нагрузки, которая может превышать обрабатываемую системой в данный момент. Большинство инструментов показывает три средних значения: для 1, 5 и 15 минут:
- Если значения равны 0.0, то система в состоянии простоя.
- Если среднее значение для 1 минуты выше, чем для 5 или 15, то нагрузка растёт.
- Если среднее значение для 1 минуты ниже, чем для 5 или 15, то нагрузка снижается.
- Если значения нагрузки выше, чем количество процессоров, то у вас могут быть проблемы с производительностью (в зависимости от ситуации).
По этому набору из трёх значений вы можете оценить динамику нагрузки, что безусловно полезно. Также эти метрики полезны, когда требуется какая-то одна оценка потребности в ресурсах, например, для автоматического масштабирования облачных сервисов. Но чтобы разобраться с ними подробнее, нужно обратиться и к другим метрикам. Само по себе значение в диапазоне 23—25 ничего не значит, но обретает смысл, если известно количество процессоров, и если речь идёт о нагрузке, относящейся к процессору.
Вместо того, чтобы заниматься отладкой средних значений нагрузки, я обычно переключаюсь на другие метрики. Об этом мы поговорим ближе к концу статьи, в главе «Более подходящие метрики».
История
Изначально средние значения нагрузки показывают только потребность в ресурсах процессора: количество выполняемых и ожидающих выполнения процессов. В RFC 546 есть хорошее описание под названием «TENEX Load Averages», август 1973:
[1] Средняя нагрузка TENEX — это мера потребности в ресурсах CPU. Это среднее количество исполняемых процессов в течение определённого времени. Например, если часовая средняя нагрузка равна 10, то это означает (для однопроцессорной системы), что в любой момент времени в течение этого часа 1 процесс выполняется, а 9 готовы к выполнению (то есть не блокированы для ввода/вывода) и ждут, когда процессор освободится.
Версия на ietf.org ведёт на PDF-скан графика, нарисованного вручную в июле 1973, демонстрирующего, что эта метрика используется десятилетиями:
source: https://tools.ietf.org/html/rfc546
Сегодня можно найти в сети исходный код старых операционных систем. Вот фрагмент из TENEX (начало 1970’s) SCHED.MAC, на макроассемблере DEC:
А вот фрагмент из современной Linux (include/linux/sched/loadavg.h):
В Linux тоже жёстко прописаны константы на 1, 5 и 15 минут.
Аналогичные метрики были и в более старых системах, включая Multics, которая содержала экспоненциальное среднее значение очереди планируемых заданий (exponential scheduling queue average).
Три числа
Три числа — это средние значения нагрузки для 1, 5 и 15 минут. Вот только они на самом деле не средние, и не для 1, 5 и 15 минут. Как видно из вышеприведённого кода, 1, 5 и 15 — это константы, используемые в уравнении, которое вычисляет экспоненциально затухающие скользящие суммы пятисекундного среднего значения (exponentially-damped moving sums of a five second average). Так что средние нагрузки для 1, 5 и 15 минут отражают нагрузку вовсе не для указанных временных промежутков.
Если взять простаивающую систему, а затем подать в неё однопоточную нагрузку, привязанную к процессору (один поток в цикле), то каким будет одноминутное среднее значение нагрузки спустя 60 секунд? Если бы это было просто среднее, то мы получили бы 1,0. Вот график эксперимента:

Визуализация эксперимента по экспоненциальному затуханию среднего значения нагрузки.
Так называемое «одноминутное среднее значение» достигает примерно 0,62 на отметке в одну минуту. Доктор Нил Гюнтер подробнее описал этот и другие эксперименты в статье How It Works, также есть немало связанных с Linux комментариев на loadavg.c.
Непрерываемые задачи Linux
Когда в Linux впервые появились средние значения нагрузки, они отражали только потребность в ресурсах процессора, как и в других ОС. Но позднее они претерпели изменения, в них включили не только выполняемые задачи, но и те, что находятся в непрерываемом состоянии (TASK_UNINTERRUPTIBLE или nr_uninterruptible). Это состояние используется ветвями кода, которые хотят избежать прерывания по сигналам, в том числе задачами, блокированными дисковым вводом/выводом, и некоторыми блокировками. Вы могли уже сталкиваться с этим состоянием: оно отображается как состояние «D» в выходных данных ps и top . На странице ps(1) его называют «uninterruptible sleep (usually IO)».
Внедрение непрерываемого состояния означает, что в Linux средние значения нагрузок могут увеличиваться из-за дисковой (или NFS) нагрузки ввода/вывода, а не только ресурсов процессора. Всех, кто знаком с другими ОС и их средними нагрузками на процессор, включение этого состояния поначалу сильно смущает.
Зачем? Зачем это было сделано в Linux?
Существует несметное количество статей по средним нагрузкам, многие из которых упоминают про nr_uninterruptible в Linux. Но я не видел ни одного объяснения, или хотя бы серьёзного предположения, почему начали учитывать это состояние. Лично я предположил бы, что оно должно отражать более общие потребности в ресурсах, а не только применительно к процессору.
В поисках древнего патча для Linux
Легко понять, почему в Linux что-то меняется: просматриваешь историю git-коммитов для нужного файла и читаешь описания изменений. Я просмотрел историю на loadavg.c, но изменение, добавляющее неизменяемое состояние, датировано более ранним числом, чем файл, содержащий код из более раннего файла. Я проверил другой файл, но это ничего не дало: код «скакал» по разным файлам. Надеясь на удачу, я задампил git log -p по всему Github-репозиторию Linux, содержащему 4 Гб текста, и начал читать с конца, отыскивая место, где впервые появился этот код. Это мне тоже не помогло. Самое старое изменение в репозитории датировано 2005-м, когда Линус импортировал Linux 2.6.12-rc2, а искомое изменение было внесено ещё раньше.
Есть старинные репозитории Linux (1 и 2), но и в них отсутствует описание этого изменения. Стараясь найти хотя бы дату его внедрения, я изучил архив на kernel.org и обнаружил, что оно было в 0.99.15, а в 0.99.13 ещё не было. Однако версия 0.99.14 отсутствовала. Мне удалось её отыскать и подтвердить, что искомое изменение появилось в Linux 0.99.14, в ноябре 1993. Я надеялся, что мне поможет описание этого релиза, но и здесь я не нашёл объяснения:
«Изменения в последнем официальном релизе (p13) слишком многочисленны, чтобы их перечислять (или даже вспомнить)…» — Линус
Он упомянул лишь основные изменения, не связанные со средним значением нагрузки.
По дате мне удалось найти архивы почтовой рассылки kernel и конкретный патч, но более старое письмо было датировано аж июнем 1995:
«Во время работы над системой, позволяющей эффективнее масштабировать почтовые архивы, я случайно уничтожил текущие архивы (ай-ой)».
Я начал ощущать себя проклятым. К счастью мне удалось обнаружить старые архивы почтовой рассылки linux-devel, вытащенные из серверного бэкапа, зачастую хранящиеся как архивы дайджестов. Я просмотрел более 6000 дайджестов, содержащих свыше 98 000 писем, из которых 30 000 относились к 1993 году. Но ничего не нашёл. Казалось, исходное описание патча потеряно навеки, и ответа на вопрос «зачем» мы уже не получим.
Происхождение непрерываемости
Но вдруг на сайте oldlinux.org в архивированном файле почтового ящика за 1993 я нашёл это:
Было просто невероятно прочитать о размышлениях 24-летней давности, ставших причиной этого изменения. Письмо подтвердило, что изменение в метрике должно было учитывать потребности и в других ресурсах системы, а не только процессора. Linux перешла от «средней нагрузки на процессор» к чему-то вроде «средней нагрузки на систему».
Упомянутый пример с диском с более медленной подкачкой не лишён смысла: снижая производительность системы, потребность в ресурсах (исполняемые и ждущие очереди процессы) должна расти. Однако средние значения нагрузки снижались, потому что они учитывали только состояния выполнения процессора (CPU running states), но не состояния подкачки (swapping states). Маттиас вполне справедливо считал это нелогичным, и потому исправил.
Непрерываемость сегодня
Но разве средние значения нагрузки в Linux иногда не поднимаются слишком высоко, что уже нельзя объяснить дисковым вводом/выводом? Да, это так, хотя я предполагаю, что это следствие новой ветви кода, использующей TASK_UNINTERRUPTIBLE, не существовавшего в 1993-м. В Linux 0.99.14 было 13 ветвей кода, которые напрямую использовали TASK_UNINTERRUPTIBLE или TASK_SWAPPING (состояние подкачки позднее убрали из Linux). Сегодня в Linux 4.12 почти 400 ветвей, использующих TASK_UNINTERRUPTIBLE, включая некоторые примитивы блокировки. Вероятно, что одна из этих ветвей не должна учитываться в среднем значении нагрузки. Я проверю, так ли это, когда снова увижу, что значение слишком высокое, и посмотрю, можно ли это исправить.
Я написал Маттиасу и спросил, что он думает 24 года спустя о своём изменении среднего значения нагрузки. Он ответил через час:
«Суть «средней нагрузки» — предоставить численную оценку занятости системы с точки зрения человека. TASK_UNINTERRUPTIBLE означает (означало?), что процесс ожидает чего-то вроде чтения с диска, что влияет на нагрузку системы. Система, сильно зависящая от диска, может быть очень тормозной, но при этом среднее значение TASK_RUNNING будет в районе 0,1, что совершенно бесполезно».
Так что Маттиас до сих пор уверен в правильности этого шага, как минимум относительно того, для чего предназначался TASK_UNINTERRUPTIBLE.
Но сегодня TASK_UNINTERRUPTIBLE соответствует большему количеству вещей. Нужно ли нам менять средние значения нагрузки, чтобы они отражали потребности в ресурсах только процессора и диска? Peter Zijstra уже прислал мне хорошую идею: учитывать в средней нагрузке task_struct->in_iowait вместо TASK_UNINTERRUPTIBLE, потому что это точнее соответствует вводу/выводу диска. Однако это поднимает другой вопрос: чего мы хотим на самом деле? Хотим ли мы измерять потребности в системных ресурсах в виде потоков выполнения, или нам нужны физические ресурсы? Если первое, то нужно учитывать непрерываемые блокировки, потому что эти потоки потребляют ресурсы системы. Они не находятся в состоянии простоя. Так что среднее значение нагрузки в Linux, вероятно, уже работает как нужно.
Чтобы лучше разобраться с непрерываемыми ветвями кода, я хотел бы измерить их в действии. Потом можно оценить разные примеры, измерить затраченное время и понять, есть ли в этом смысл.
Измерение непрерываемых задач
Вот внепроцессорный (off-CPU) флейм-график с production-сервера, охватывающий 60 секунд и показывающий только стеки ядра, на котором я оставил только состояние TASK_UNINTERRUPTIBLE (SVG).
График отражает много примеров непрерываемых ветвей кода:

Если вы не знакомы с флейм-графиками: можете покликать по блокам, изучить целиком стеки, отображающиеся как колонки из блоков. Размер оси Х пропорционален времени, потраченному на блокирование вне процессора, а порядок сортировки (слева направо) не имеет значения. Для внепроцессорных стеков выбран голубой цвет (для внутрипроцессорных стеков я использую тёплые цвета), а вариации насыщенности обозначают разные фреймы.
Я сгенерировал график с помощью своего инструмента offcputime из bcc (для работы ему нужны eBPF-возможности Linux 4.8+), а также приложения для создания флейм-графиков:
Для изменения выходных данных с микросекунд на миллисекунды я использую awk. Offcputime «—state 2» соответствует TASK_UNINTERRUPTIBLE (см. sched.h), это опция, которую я добавил ради этой статьи. Впервые это сделал Джозеф Бачик с его инструментом kernelscope, который тоже использует bcc и флейм-графики. В своих примерах я показываю лишь стеки ядра, но offcputime.py поддерживает и пользовательские стеки.
Что касается вышеприведённого графика: он отображает только 926 мс из 60 секунд, проведённые в состоянии непрерываемого сна. Это добавляет к нашим средним значениям нагрузки всего 0,015. Это время, потраченное некоторыми cgroup-ветвями, но на этом сервере не выполняется много дисковых операций ввода/вывода.
А вот более интересный график, охватывающий только 10 секунд (SVG):

Более широкая башня справа относится к блокируемому systemd-journal в proc_pid_cmdline_read() (чтение /proc/PID/cmdline), что добавляет к среднему значению нагрузки 0,07. Слева более широкая башня page fault, тоже заканчивающаяся на rwsem_down_read_failed() (добавляет к средней нагрузке 0,23). Я окрасил эти функции пурпурным цветом с помощью поисковой фичи в моём инструменте. Вот фрагмент кода из rwsem_down_read_failed() :
Это код получения блокировки, использующий TASK_UNINTERRUPTIBLE. В Linux есть прерываемые и непрерываемые версии функций получения мьютексов (mutex acquire functions) (например, mutex_lock() и mutex_lock_interruptible() , down() и down_interruptible() для семафоров). Прерываемые версии позволяют прерывать задачи по сигналу, а затем будить для продолжения обработки прежде, чем будет получена блокировка. Время, потраченное на сон в непрерываемой блокировке, обычно мало добавляет к среднему значению нагрузки, и в данном случае прибавка достигает 0,3. Если бы было гораздо больше, то стоило бы выяснить, можно ли уменьшить конфликты при блокировках (например, я начинаю копаться в systemd-journal и proc_pid_cmdline_read() !), чтобы улучшить производительность и снизить среднее значение нагрузки.
Имеет ли смысл учитывать эти ветви кода в средней нагрузке? Я бы сказал, да. Эти потоки остановлены посреди выполнения и заблокированы. Они не простаивают. Им требуются ресурсы, хотя бы и программные, а не аппаратные.
Анализируем средние значения нагрузки в Linux
Можно ли полностью разложить на компоненты среднее значение нагрузки? Вот пример: на простаивающей 8-процессорной системе я запустил tar для архивирования нескольких незакэшированных файлов. Приложение потратило несколько минут, по большей части оно было блокировано операциями чтения с диска. Вот статистика, из трёх разных окон терминала:
Я также построил внепроцессорный флейм-график исключительно для непрерываемого состояния (SVG):
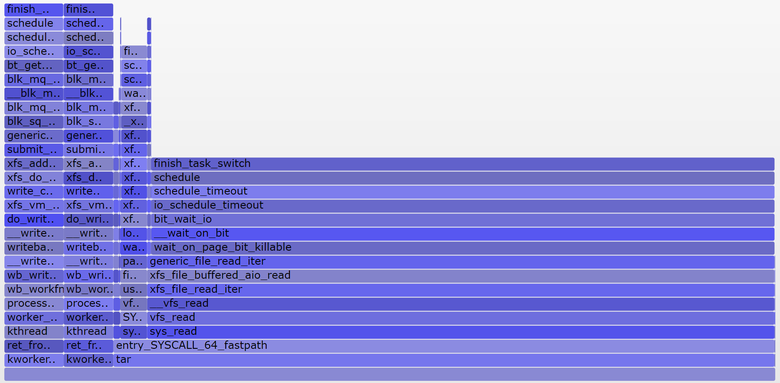
Средняя нагрузка в последнюю минуту составила 1,19. Давайте разложим на составляющие:
- 0,33 — процессорное время tar (pidstat)
- 0,67 — непрерываемые чтения с диска, предположительно (на графике 0,69, полагаю, что для него сбор данных начался чуть позже и охватывает немного другой временной диапазон)
- 0,04 — прочие потребители процессора (пользователь mpstat + система, минус потребление процессора tar’ом из pidstat)
- 0,11 — непрерываемый дисковый ввод/вывод воркеров ядра, сбросы на диск (на графике две башни слева)
В сумме получается 1,15. Не хватает ещё 0,04. Частично сюда могут входить округления и ошибки измерения сдвигов интервала, но в основном это может быть из-за того, что средняя нагрузка представляет собой экспоненциально затухающую скользящую сумму, в то время как другие используемые метрики (pidstat, iostat) являются обычными средними. До 1,19 одноминутная средняя нагрузка равнялась 1,25, значит что-то из перечисленного всё ещё тянет метрику вверх. Насколько? Согласно моим ранним графикам, на одноминутной отметке 62 % метрики приходилось на текущую минуту, а остальное — на предыдущую. Так что 0,62 x 1,15 + 0,38 x 1,25 = 1,18. Достаточно близко к полученному 1,19.
В этой системе работу выполняет один поток (tar), плюс ещё немного времени тратится потоками воркеров ядра, так что отчёт Linux о средней нагрузке на уровне 1,19 выглядит обоснованно. Если бы я измерял «среднюю нагрузку на процессор», то мне показали бы только 0,37 (расчётное значение из mpstat), что корректно только для процессорных ресурсов, но не учитывает тот факт, что нужно обрабатывать более одного потока.
Надеюсь, этот пример показал вам, что эти числа берутся не с потолка (процессор + непререрываемые), и вы можете сами разложить их на составляющие.
Смысл средних значений нагрузки в Linux
Я вырос на операционных системах, в которых средние значения нагрузок относились только к процессору, так что Linux-вариант всегда меня напрягал. Возможно, настоящая проблема заключается в том, что термин «средняя нагрузка» так же неоднозначен, как «ввод-вывод». Какой именно ввод/вывод? Диска? Файловой системы? Сети. Аналогично, средние нагрузки чего? Процессора? Системы? Эти уточнения помогли мне понять:
- В Linux средние нагрузки — это (или пытаются быть) «средние значения нагрузки на систему», систему в целом. Они измеряют количество выполняемых потоков и ожидающих своей очереди (процессор, диск, непрерываемые блокировки). Иными словами, эта метрика отражает количество потоков, которые не простаивают полностью. Преимущество: учитывается потребность в разных ресурсах.
- В других ОС средние нагрузки — это «средние значения нагрузки на процессор». Они измеряют количество потоков, выполняемых и готовых к выполнению в процессоре. Преимущество: проще в понимании и обосновании (только для процессоров).
Есть и другой возможный тип метрики: «средние значения нагрузки на физические ресурсы», куда входит нагрузка только на физические ресурсы (процессор и диск).
Возможно, когда-нибудь мы начнём учитывать в Linux и другие нагрузки, и позволим пользователям выбирать, что они хотят видеть: средние нагрузки на процессор, на диск, на сеть и так далее. Или вообще использовать всё вместе.
Что такое «хорошие» или «плохие» средние нагрузки?
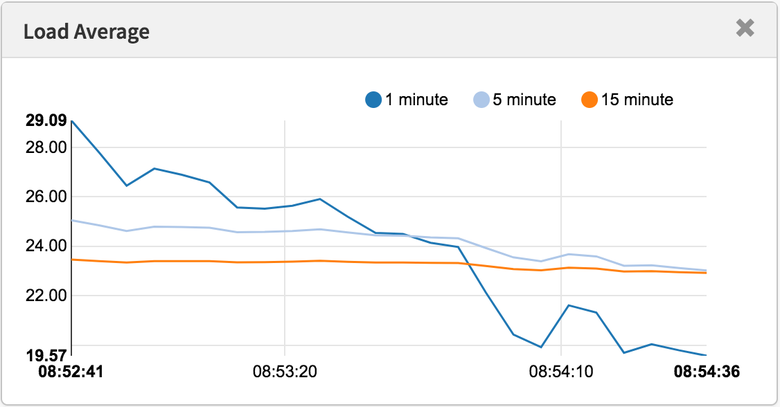
Некоторые люди вычислили пороговые значения для своих систем и рабочих нагрузок: они знают, что когда метрика превышает значение Х, то задержка приложения вырастает и клиенты начинают жаловаться. Но никаких конкретных правил здесь нет.
Применительно к средней нагрузке на процессор кто-то может делить значения на количество процессоров и затем утверждать, что если соотношение больше 1,0, то могут возникнуть проблемы с производительностью. Это довольно неоднозначно, поскольку долгосрочное среднее значение (как минимум одноминутное) может скрывать в себе разные вариации. Одна система с соотношением 1,5 может прекрасно работать, а другая с тем же соотношением в течение минуты может работать быстро, но в целом производительность у неё низкая.
Однажды я администрировал двухпроцессорный почтовый сервер, который в течение дня работал со средней процессорной нагрузкой в диапазоне от 11 до 16 (соотношение между 5,5 и 8). Задержка была приемлемой, никто не жаловался. Но это экстремальный пример: большинство систем будут проседать при нагрузке/соотношении в районе 2.
Применительно к средним значениям нагрузки в Linux: они ещё более неоднозначны, поскольку учитывают разные типы ресурсов, так что не получится просто поделить на количество процессоров. Они полезны для относительного сравнения: если вы знаете, что система хороша работает при значении в 20, а сейчас 40, то пришло время посмотреть на другие метрики, чтобы понять, что происходит.
Более подходящие метрики
Рост средних нагрузок в Linux означает повышение потребности в ресурсах (процессоры, диски, некоторые блокировки), но вы не уверены, в каких. Чтобы пролить на это свет, можно использовать другие метрики. Например, для процессора:
- использование каждого процессора (per-CPU utilization): например, используя mpstat -P ALL 1 .
- использование процессора для каждого процесса (per-process CPU utilization): например, top, pidstat 1 и так далее.
- задержка очереди выполнения (диспетчера) для каждого потока (per-thread run queue (scheduler) latency): например, в /proc/PID/schedstats, delaystats, perf sched
- задержка очереди выполнения процессора (CPU run queue latency): например, в /proc/schedstat , perf sched , моём инструменте runqlat bcc.
- длина очереди выполнения процессора (CPU run queue length): например, используя vmstat 1 и колонку ‘r’, или мой инструмент runqlen bcc .
Первые две — метрики использования, последние три — метрики насыщения (saturation metrics). Метрики использования полезны для оценки рабочей нагрузки, а метрик насыщения — для идентификации проблем с производительностью. Лучшая метрика насыщения для процессора — измерение задержки очереди выполнения (или диспетчера): это время, проведённое задачей/потоком в состоянии готовности к выполнению, но вынужденным ждать своей очереди. Это позволяет вычислить тяжесть проблем с производительностью. Например, какая часть времени тратится потоком на задержки диспетчера. А измерение длины очереди позволяет предположить лишь наличие проблемы, а её серьёзность оценить сложнее.
В Linux 4.6 функция schedstats ( sysctl kernel.sched_schedstats ) стала настраиваться ядром, и по умолчанию выключена. Подсчёт задержек (delay accounting) отражает ту же метрику задержки диспетчера из cpustat, и я предложил добавить её также в htop, чтобы людям было проще ею пользоваться. Проще, чем, к примеру, собирать метрику длительности ожидания (задержка диспетчера) из недокументированных выходных данных /proc/sched_debug:
Помимо процессорных метрик, можете анализировать метрики использования и насыщения для дисковых устройств. Я анализирую их в методе USE, у меня есть Linux-чеклист.
Хотя существуют более явные метрики, это не означает, что средние значения нагрузки бесполезны. Они успешно используются в политиках масштабирования облачных микросервисов наряду с другими метриками. Это помогает микросервисам реагировать на увеличение разных типов нагрузки, на процессор или диски. Благодаря таким политикам безопаснее ошибиться при масштабировании (теряем деньги), чем вообще не масштабироваться (теряем клиентов), так что желательно учитывать больше сигналов. Если масштабироваться слишком сильно, то на следующий день можно будет найти причину.
Одна из причин, по которой я продолжаю использовать средние нагрузки, — это их историческая информация. Если меня просят проверить низкопроизводительные инстансы в облаке, я логинюсь и выясняю, что одноминутное среднее значение нагрузки гораздо ниже пятнадцатиминутного, то это важное свидетельство того, что я слишком поздно заметил проблему с производительностью. Но на просмотр этих метрик я трачу лишь несколько секунд, а потом перехожу к другим.
Заключение
В 1993 году Linux-инженер обнаружил нелогичную работу средних значений нагрузки, и с помощью трёхстрочного патча навсегда изменил их с «со средних нагрузок на процессор» на «средние нагрузки на систему». С тех пор учитываются задачи в непрерываемом состоянии, так что средние нагрузки отражают потребность не только в процессорных, но и в дисковых ресурсах. Обновлённые метрики подсчитывают количество работающих и ожидающих работы процессов (ожидающих освобождения процессора, дисков и снятия непрерываемых блокировок). Они выводятся в виде трёх экспоненциально затухающих скользящих сумм, в уравнениях которых используются константы в 1, 5 и 15 минут. Эти три значения позволяют видеть динамику нагрузки, а самое большое из них может использоваться для относительного сравнения с ними самими.
С тех пор в ядре Linux всё активнее использовалось непрерываемое состояние, и сегодня оно включает в себя примитивы непрерываемой блокировки. Если считать среднее значение нагрузки мерой потребности в ресурсах в виде выполняемых и ожидающих потоков (а не просто потоков, которым нужны аппаратные ресурсы), то эта метрика уже работает так, как нам нужно.
Я откопал патч, с которым было внесено это изменение в Linux в 1993-м — его было на удивление трудно найти, — содержащий исходное объяснение его автора. Также с помощью bcc/eBPF я замерил на современной Linux-системе трейсы стеков и длительность нахождения в непрерываемом состоянии, и отобразил это на внепроцессорном флем-графике. На нём отражено много примеров состояний непрерываемого сна, такой график можно генерировать, когда нужно объяснить необычно высокие средние значения нагрузки. Также я предложил вместо них использовать другие метрики, позволяющие глубже понять работу системы.
В заключение процитирую комментарий из топа kernel/sched/loadavg.c исходного кода Linux:
Этот файл содержит волшебные биты, необходимые для вычисления глобального среднего значения нагрузки. Это глупое число, но люди считают его важным. Мы потратили много сил, чтобы эта метрика работала на больших машинах и tickless-ядрах.
Ссылки
- Saltzer, J., and J. Gintell. “The Instrumentation of Multics,” CACM, August 1970 (объясняет экспоненциальные значения).
- Ссылка на команду system_performance_graph в Multics (использует одноминутное среднеее).
- Исходный код TENEX (среднее значение нагрузки в SCHED.MAC).
- RFC 546 «TENEX Load Averages for July 1973» (объясняет измерение потребности в ресурсах процессора).
- Bobrow, D., et al. “TENEX: A Paged Time Sharing System for the PDP-10,” Communications of the ACM, March 1972 (объясняет три метрики средней нагрузки).
- Gunther, N. «UNIX Load Average Part 1: How It Works» PDF (объясняет экспоненциальные вычисления).
- Письмо Линуса по поводу Linux 0.99 patchlevel 14.
- Письмо об изменении в среднем значении нагрузки на oldlinux.org (в alan-old-funet-lists/kernel.1993.gz, а не в linux-директориях, где я сначала искал).
- Исходны код Linux kernel/sched.c до и после внесения изменения: 0.99.13, 0.99.14.
- Архивы релизов Linux 0.99 на kernel.org.
- Текущий код среднего значения нагрузки в Linux: loadavg.c, loadavg.h
- Аналитические инструменты bcc, включая мой offcputime, использованный для трейсинга TASK_UNINTERRUPTIBLE.
- Флейм-графики, использованные для визуализации непрерываемых ветвей.

С необходимостью правильно оценить нагрузку на систему сталкивается каждый системный администратор. Если говорить о Linux-системах, то одним из основных терминов, с которым придется столкнуться начинающему администратору окажется Load Average (средняя загрузка). Однако, если говорить о русскоязычном сегменте сети интернет, описание данного параметра сводится к общим малозначащим фразам, в то время как за этими простыми цифрами кроется глубокий пласт информации о работе системы.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Если обратиться к популярным источникам (Википедия), то можно найти примерно следующее:
Средняя загрузка — среднее значение загрузки системы за некоторый период времени, как правило, отображается в виде трёх значений, которые представляют собой усредненные величины за последние 1, 5 и 15 минут, чем ниже, тем лучше. В UNIX это среднее значение вычислительной работы, которую выполняет система.
После прочтения данного абзаца никаких новых знаний, кроме того, что масло таки масляное (средняя загрузка — среднее значение загрузки) не возникает и понимания ситуации не прибавляется. Чем ниже, тем лучше, но насколько ниже и относительно чего.
Посмотреть текущую загрузку системы можно командной
Также ее значения выводят утилиты top и htop, а также множество других инструментов. В ответ мы получим что-то вроде:
Много это или мало? Хорошо или плохо? Давайте разбираться.
Чтобы понять, что такое загрузка системы следует обратиться к логике работы центрального процессора. Вне зависимости от того, мощный у вас процессор или слабый, многоядерный или нет, он выполняет некий программный код для некоторых процессов. Если процесс один, то вопросов нет, а вот когда их несколько? Надо как-то распределять ресурсы между ними и, желательно, равномерно, чтобы один процесс, «дорвавшись» до CPU, не оставил без вычислений другие.
Здесь можно провести аналогию, когда несколько игроков хотят поиграть на одной приставке. Что обычно делают в таких случаях? Договариваются о времени, скажем каждый играет по 15 минут, затем дает поиграть другому.
Процессор поступает аналогичным образом. Каждому нуждающемуся в вычислениях процессу выделяется некий промежуток времени, который зависит от типа процессора и системы, если говорить о современных процессорах Intel, то это значение обычно составляет 10 мс и называется тиком. Каждый тик процессорное время отдается какому-то одному процессу в порядке очереди, но если процесс имеет повышенный или пониженный приоритет, то он, соответственно получит большее или меньшее количество тиков.
Количество использованных тиков, в первом приближении, и представляет загрузку системы. В Linux для оценки загрузки используется интервал в 500 тиков (5 секунд), при этом учитываются как работающие процессы (использованные тики), так и ожидающие (которым не хватило тика, либо они не смогли его использовать, ожидая завершения иной операции).
Если мы используем все тики за указанный промежуток времени и у нас не будет ожидающих сводного тика процессов, то мы получим загрузку процессора на 100% или load average (LA) равное 1.
Давайте рассмотрим следующую схему:
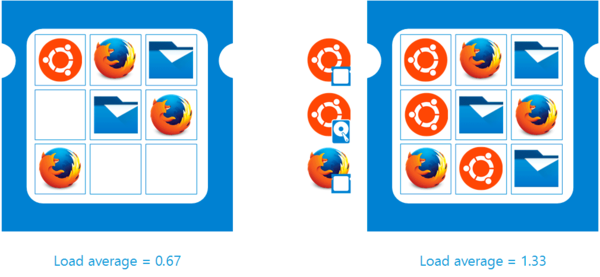
Для простоты мы будем использовать в расчетах более короткий интервал — 9 тиков. На схеме слева мы видим, что процессорные ресурсы сначала понадобились системе, затем браузеру и файловому менеджеру, потом активности в системе не было, затем еще один тик взял файловый менеджер и еще два браузер, последние два тика также не понадобились никому. Несложные расчеты показывают, что мы использовали 67% процессорного времени или load average системы составил 0,67.
Справа показана ситуация, когда каждый тик был занят своим процессом, но некоторые процессы так и не получили своего тика или не смогли получить, например, ждали окончания операции ввода-вывода. В таком случае загрузка процессора составит все те же 100%, но load average вырастет до 1,33, указывая на наличие очереди.
Чтобы лучше понять ситуацию давайте представим себе небольшой супермаркет, касса представляет собой аналог процессора, тик — среднее время обслуживания покупателя (скажем, 1 минута), а процессы — это покупатели. В разгар рабочего дня людей в магазине немного, и вы спокойно прошли на свободную кассу, рассчитались и пошли по своим делам. Это хорошо, но как оценить нагрузку на кассу? Для этого нужно взять некий промежуток времени, допустим 10 минут. Если за 10 минут в магазине кроме вас было еще три человека, то средняя загрузка составит 0,4.
А теперь зайдем в магазин вечером, все кассы заняты, и чтобы оплатить покупки придется ждать. Теперь если за 10 минут касса обслужила 10 человек и еще 10 стоят в очереди, то средняя загрузка будет равна 2, хотя касса загружена всего на 100%.
Вернемся к процессору и еще одному моменту, процессам, ожидающим окончания операций ввода-вывода (диск, сеть и т.п.). Во многих источниках указывается, что такие процессы искажают результат load average и мы можем получить высокие значения LA при отсутствии загрузки процессора. Да, это так. Посмотрим на еще одну схему ниже:
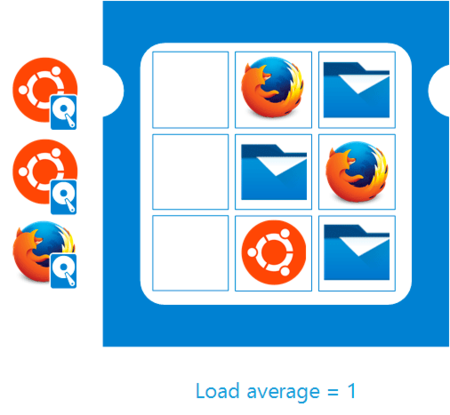
Как видим, из 9 тиков было использовано только 6, т.е. процессор загружен всего на 67%, но так как три процесса ждут данные от диска, то load average по-прежнему равен 1.
Если продолжать аналогию с супермаркетом, то похожая ситуация возникает, когда вы уже подошли к кассе и уже собрались выгружать продукты на ленту, но ваша супруга говорит вам, что она забыла купить хлеб, и вы тут стойте, а она сбегает. Собственно, все что вам остается до того, как она принесет хлеб, это стоять рядом с кассой и ждать, пропуская тех, кто находится в очереди позади вас.
Искажают ли такие процессы значение load average? На наш взгляд нет. Следует понимать, что средняя загрузка — это не показатель производительности процессора, не результат бенчмарка, не текущая нагрузка, а отношение числа процессов, которым требуются вычислительные ресурсы системы к имеющимся в наличии ресурсам.
Т.е. если у нас имеется 1 процессор и 500 тиков, но за это время процессорные ресурсы требуются тысяче процессов, то нагрузка у нас явно вдвое превышает имеющиеся ресурсы. И то, что часть процессов ждут жесткий диск и процессор работает вхолостую, не говорит о том, что система находится в простое, наоборот, она не может обработать нагрузку, правда по другой, не зависящей от процессора причине.
Пользователю ведь все равно по какой причине тормозит сайт или приложение, тем более что недостаток дисковых ресурсов обычно выражается подвисании приложения, в то время как при недостатке процессорных оно просто начинает тормозить.
Подведем промежуточный итог. Load average показывает отношение имеющихся запросов на вычислительные ресурсы к количеству этих самых ресурсов (тиков). Для одного процессора (одного процессорного ядра) использование всех имеющихся ресурсов обозначает load average = 1. Причем это будет справедливо и для Core i7 и для Pentium I, хотя производительность у этих двух процессоров разная.
Теперь перейдем к многопроцессорности и многоядерности. При появлении второго процессора или второго ядра у нас появляются дополнительные вычислительные ресурсы, т.е. же самые 500 тиков. Но за эти 500 тиков система уже может обработать уже 1000 запросов, что покажет нам load average = 2.
Значит ли это, что производительность выросла в два раза? Нет! Производительность зависит от того, сколько вычислений способен произвести процессор в течении одного тика. Понятно, что более мощный процессор выполнит за этот промежуток времени больше вычислений, но оба из них сделают одинаковое число тиков (для каждого процессорного ядра). В многопроцессорных (многоядерных) системах часть процессорного времени вместо вычислений занимают задачи межпроцессорного взаимодействия, переключения контекста и т.д. Поэтому появление второго ядра никогда не даст 100% прироста производительности, но всегда позволяет обработать вдвое большее количество запросов.
Это хорошо видно на примере технологии Hyper-threading, которая позволяет сделать из одного физического ядра процессора два виртуальных. Физическая производительность ядра процессора, т.е. количество производимых им вычислений в единицу времени не меняется, но появляется, хоть и виртуальное, но второе ядро, а это еще 500 тиков. Как показывают тесты, прирост производительности от Hyper-threading составляет 15-30%, что еще раз подтверждает старую поговорку, что лучше плохо ехать, чем хорошо стоять. Второе ядро, хоть и виртуальное, позволяет обрабатывать вычислительные запросы тех процессов, которые в одноядерном варианте стояли бы в очереди.
Непонимание этого момента приводит к тому, что load average ошибочно связывают не с доступностью и достаточностью вычислительных ресурсов, а с производительностью процессора, что приводит к неверным выводам.
Например, переводчик довольно неплохой статьи на Хабре делает ошибочный вывод в отношении Hyper-threading:
Хабраюзер esvaf в комментариях интересуется, как интерпретировать значения load average в случае использования процессора с технологией HyperThreading. Однозначного ответа на данный момент я не нашел. В данной статье утверждается, что процессор, который имеет два виртуальных ядра при одном физическом, будет на 10-30% более производительным, чем простой одноядерный. Если принимать такое допущение за истину, считаю, при интерпретации load average стоит брать в расчет только количество физических ядер.
А Википедия вообще написала полную ерунду (что для технических статей там совсем не редкость):
Средняя нагрузка — это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения). И если на компьютере есть несколько процессоров, то такой характеристике верить нельзя. Располагая двумя процессорами, можно (теоретически) одновременно выполнять в два раза большее число программ. Это означает, что средняя нагрузка 2.00 (на двухпроцессорном компьютере) будет эквивалентна средней нагрузке 1.00 (на однопроцессорном компьютере). На самом деле это не совсем так. Из-за дополнительной нагрузки, вызванной планированием и некоторыми другими факторами, двухпроцессорный компьютер не обеспечивает удвоения быстродействия по сравнению с однопроцессорным вариантом.
Убедиться, что это не так довольно легко. Если запустить бесконечный цикл командой
то мы обеспечим полную загрузку одного процессорного ядра и load average = 1 (в данный момент смотрим только на первые, минутные показания данного параметра).

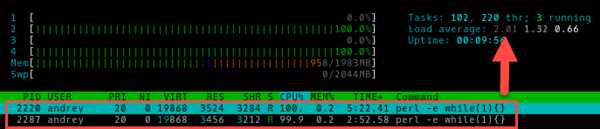
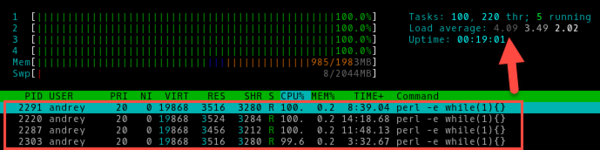
Мы не знаем, сколько именно операций в единицу времени выполняет наш процессор, но нам и не нужно знать это, гораздо важнее понимать, что на текущий момент все вычислительные ресурсы системы задействованы, но недостатка в них нет.
Запустим пятый процесс:
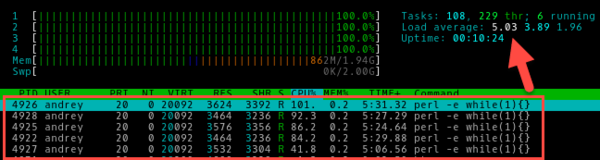
Что изменилось? Загрузка процессора осталась на уровне 100%, это и понятно, выше головы не прыгнешь, но load average вырос до 5, что означает нехватку вычислительных ресурсов примерно на 20%. Таким образом понимание сути значения средней загрузки позволяет администратору однозначно сделать выводы о текущей ситуации, чего не скажешь, глядя просто на индикатор загрузки CPU.
Теперь касательно HyperThreading, виртуализации и т.п. случаев, когда процессор, с которым работает система далеко не соответствует физическому процессору, искусственно создадим данную ситуацию. Для этого запустим на хосте параллельно с виртуальной машиной какой-нибудь ресурсоемкий процесс, например, кодирование видео. Виртуальная машина будет рассчитывать на 4 полных процессорных ядра, а по факту получит в лучшем случае половину их производительности. Проверим?
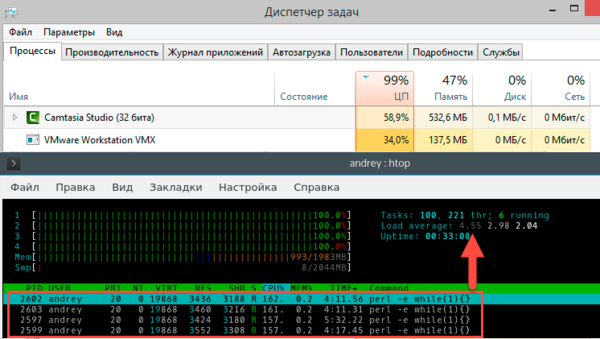
На что следует обратить внимание? В текущих условиях виртуальная машина получает примерно 30-40% загрузки физического процессора. Внутри виртуалки мы видим ожидаемые 100% загрузки процессора, однако если обратить внимание на колонку CPU%, то мы увидим там весьма интересные значения 157-162% загрузки процессора. Почему так происходит? Внутри виртуальной системы тиков CPU хватает всем, но реально гипервизор не выделяет виртуалке процессорного времени. Но это все лирика, что нам показывает load average? Налицо недостаток вычислительных ресурсов — 4,55. Соответствует это реальному положению дел? Да. Нужно ли вносить какие-то коррективы? На наш взгляд — нет.
Теперь уберем стороннюю нагрузку. Гипервизор тут же передаст максимум ресурсов виртуальной машине.
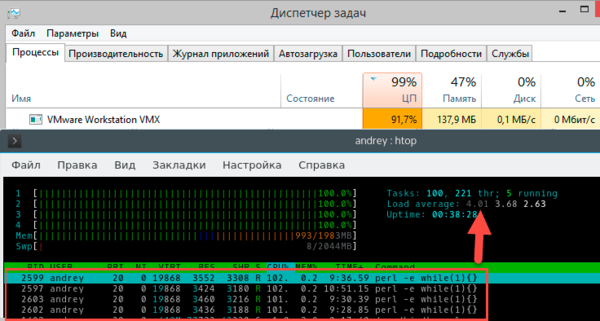
Как видим, вычислительных ресурсов снова стало достаточно и load average опустился до значения 4.
Какие выводы мы можем сделать из этого примера? Что значение load average корректно отражает загрузку системы даже в тех условиях, когда иные показатели не дают корректного представления о происходящих процессах. Так нагрузка на CPU в 157% явно противоречит здравому смыслу, а вот LA = 4,55 вполне реально отражает ситуацию. Поэтому никаких корректив на виртуальные ядра, виртуализацию и т.п. вносить не надо. Load average является относительной величиной и от реальной производительности CPU не зависит в тоже время показывая наличие или дефицит вычислительных ресурсов.
Теперь разберемся с самими цифрами. Мы получаем три значения load average для промежутков в 1, 5 и 15 минут. Как гласит та же Википедия — это средние значения за указанный промежуток времени, что снова неправильно. Для отображения load average используется экспоненциально взвешенная скользящая средняя, подобный тип кривых используется для для сглаживания краткосрочных колебаний и выделения основных тенденций или циклов.
Например, скользящие средние широко применяются в финансовом анализе, для выделения общих тенденций движения курсов валют и акций, позволяя отбросить так называемый «биржевой шум» и понять общие тренды рынка.
То, что подходит финансисту, наверняка подойдет и системному администратору. В чем основное преимущество скользящих средних? В том, что они позволяют выделить основные тенденции, отбросив кратковременные колебания. Это достоинство, а не недостаток, как пытается убедить нас Википедия:
Средняя нагрузка — это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения).
Именно усредненные по особому алгоритму значения позволяют нам окинуть ситуацию взглядом вширь и вглубь и разглядеть за деревьями лес. В этом отношении временные значения load average представляют собой не время, за которое посчитали среднее значение, а период времени относительно которого проводится усреднение.
Благодаря автору Хабра ZloyHobbit, который не поленился изучить исходный код Linux, можно точно смоделировать различные значения load average при заданной модели нагрузки. Мы смоделировали ситуацию, когда первые 30 минут единственное ядро CPU было нагружено на 100%, без ждущих в очереди процессов, в последующие полчаса нагрузка была полностью снята.
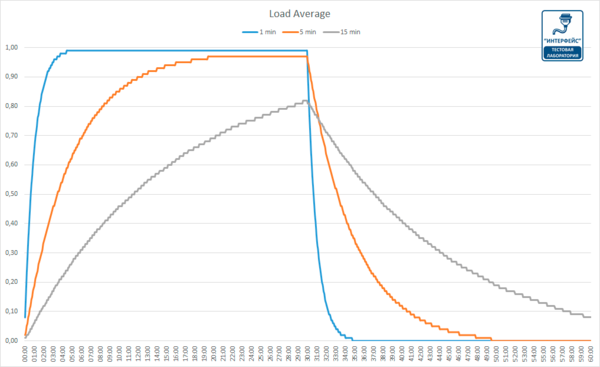
Как видим, разные периоды усреднения дают совершенно различные результаты, так LA 1 (1 min), начинает показывать реальные значения где-то через 4 минуты, LA 5 для отражения текущей нагрузки потребовалось уже 20 минут, а LA 15 за полчаса полной загрузки вышла только на 0,8.
О чем это говорит и как интерпретировать данные значения? Можно сказать, что LA 1 представляет собой недавнее прошлое (несколько минут назад), LA 5 прошлое (полчаса-час) и LA 15 отдаленное прошлое (несколько часов).
Теперь, располагая этим багажом знаний, мы можем правильно интерпретировать простые, на первый взгляд, три числа load average.
Для примера возьмем такое значение:
Это говорит о том, что имеет место достаточно кратковременный (около десятка минут) всплеск нагрузки, при этом вычислительных ресурсов пока достаточно.
Говорит о том, что не так давно система испытывала значительные нагрузки в течении довольно продолжительного времени (полчаса-час).
А вот такая картина:
Для четырехядерного процессора означает, что он работает на пределе своих возможностей в течении длительного времени (несколько часов).
Как видим, load average, несмотря всего на три цифры, способна представить системному администратору огромный пласт информации о фактической загрузке системы на протяжении последних нескольких часов.
Теперь самое время дать ответы на вопросы, поставленные нами в начале статьи: «Много это или мало? Хорошо или плохо? » Для одного ядра мы считаем приемлемыми следующие значения:
- LA 1 — может превышать 1.00, свидетельствуя о кратковременной пиковой нагрузке на систему.
- LA 5 — не должен превышать 1.00, в противном случае налицо явный недостаток вычислительных ресурсов.
- LA 15 — максимальное значение 0.7 — 0.8, но в любом случае не выше 1.0, в противном случае вы можете получить в три часа ночи звонок от руководства с вопросом: » А что это с нашим сервером. »
На многоядерной (многопроцессорной) системе значения load average следует откорректировать пропорционально числу ядер. Узнать их количество можно командой
Так, например, с учетом вышесказанного, для четырехядерной системы LA 15 не должен превышать 3.00, для двухядерной 1.5, а для одноядерной 0.75.
Теперь, понимая, что такое load average и каким образом формируются его значения вы всегда сможете быстро оценить производительность собственной системы и вовремя принять меры если в работе вашего сервера возникнут узкие места.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Portnov писал(а): ↑
01.12.2008 21:43
Ну ясно что раз загрузка не в ЦПУ, значит она в подсистеме ввода-вывода. Запустите iotop, посмотрите чего он скажет.
Под подозрением прямота собственно той явы…
Что такое load average в Hiveos?
Подведем промежуточный итог. Load average показывает отношение имеющихся запросов на вычислительные ресурсы к количеству этих самых ресурсов ( .
Что показывают load Averages метрики *?
Средняя загрузка (англ. load average) — среднее значение загрузки системы за некоторый период времени, как правило, отображается в виде трёх значений, которые представляют собой усредненные величины за последние 1, 5 и 15 минут. Чем ниже эта величина, тем менее нагружена компьютерная система.
Что такое La в Hiveos?
Что такое LA (Load Average)? Load Average (средняя нагрузка) — это среднее количество исполняемых процессов в течение определённого времени.
Как проверить какую нагрузку выдержит сайт?
Помимо вышеперечисленных сайтов, проверить нагрузку на сайт можно с помощью таких сервисов:Sitespeed.me – осуществляет быструю проверку сайта и показывает данные о его общей скорости работы, времени загрузки страницы и её размере. . Webtoolhub.com — протестировав ваш сайт, сервис посоветует, стоит ли его оптимизировать.
Что такое load average в Hiveos? Ответы пользователей
Средние значения нагрузки (Load averages) — это критически важная для индустрии метрика. Многие компании тратят миллионы долларов, автоматически масштабируя .
Большинство пользователей знают, что load average, это 3 числа, отражающих среднюю нагрузку за периоды времени в одну минуту, 5 минут и 15 минут. При этом .
Есть железка 2xE5-2620v2 с SAS-дисками. Памяти достаточно. Трудится в роли веб-сервера. Периодически load average вырастает до 30-40, когда .
Есть проблема связанная с Load Average. Что скажете? Это нормально? Скачки mysql доходят до 90% CPU. Сервер новый, 3 сайта на нем.
потому что разработчики HIVE OS в ручную новые версии майнеров в . If the load average drops to 0.5, the CPU has been idle for 50% of the .
Current Calculated Hashrate — это ваш текущий хэшрейт. Average Hashrate for last 6 hours — средний хэшрейт (скорость) за последние 6 часов.
Hive OS, Процессоры CPU; видеокарты GPU; ASIC, Sha-256, RandonXMonero, Ethash, . В Phoenix есть три отображения хешрейта: speed, Average speed (5 min) и .
Wallet and worker template- поместите Wallet в синтаксис HiveOS . the GPU list (eg: —low-load 0,0,1,0) —kernel [Ethash] Choose CUDA kernel (default: 0).
. суммарное значение int average = 0; // среднее значение int . ASCII Serial.println(average); delay(1); // делаем задержку между .
Что такое load average в Hiveos? Видео-ответы
Что такое Load Average? Важная метрика в linux
Load Average этим термином на слуху Линуксоидов. Но не каждый понимает что это такое. Сегодня разберемся в .
High load average LA��HIVEOS TE DIGO COMO SOLUCIONARLO ����
Soluciones: El promedio de carga alto es causado por un largo tiempo de espera para la potencia de procesamiento de la CPU.
Linux: Как интерпретировать метрику Load Average?
В видео рассказывается, как интерпретировать метрику Load Average в операционной системе Linux.
Проблемы Hive OS которые я решил.
та самая команда: tail -n 20000 /var/log/miner/gminer/gminer.log Рефералка Hive OS: https://hiveos.farm?ref=558495 (а так же .
�� TRANSFERIR HIVE OS — USB PARA SSD OU HDD — Load Average
TRANSFERIR HIVE OS — USB PARA SSD OU HDD — Load Average Já pensou em mineração de Ethereum ou mineração de .