Фундаментальные структуры данных
Всем привет! Сегодня речь пойдет о фундаментальных структурах данных, которые я изучил на очередном курсе Высшей школы программирования Сергея Бобровского. Эта статья будет некой шпаргалкой, куда можно будет заглянуть и увидеть основные особенности некоторых базовых типов данных.
Связанный список
Первой структурой данных, показанной на курсе, был связанный список, ниже представлена схема его устройства. 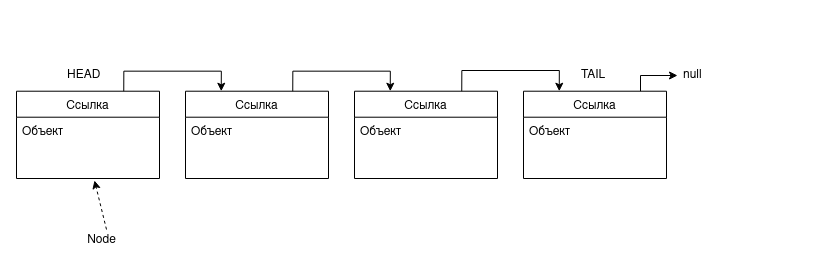 Всё довольно просто. У нас есть набор узлов (Node), которые содержат какое-то значение (число, строка или ещё что-то) и ссылку на другой узел. Первый и последний узлы списка называются HEAD и TAIL соответственно. Для реализации такого списка нам нужно два класса: Node, который описывает узел и LinkedList, определяющий наш список.
Всё довольно просто. У нас есть набор узлов (Node), которые содержат какое-то значение (число, строка или ещё что-то) и ссылку на другой узел. Первый и последний узлы списка называются HEAD и TAIL соответственно. Для реализации такого списка нам нужно два класса: Node, который описывает узел и LinkedList, определяющий наш список.
Как видно из схемы, перемещаться по узлам мы можем только вперёд.
Преимущества
- Очень быстрая операция вставки/удаления элемента, для вставки узла в середину нам достаточно изменить всего 2 ссылки.
- Элементы могут храниться в различных областях памяти. Список легко меняет свой размер.
- Легко выделить часть списка, просто изменив поля HEAD и TAIL.
Недостатки
- Чтобы обратиться к элементу необходимо перебрать всех его предшественников.
- Время доступа к узлам больше чем в массиве, так как они хранятся в разных областях памяти.
- Можно двигаться лишь в одном направлении.
Двунаправленный cвязанный список
Эта структура данных убирает один из недостатков связанного списка: возможность движения только в одном направлении. Её устройство представлено ниже. 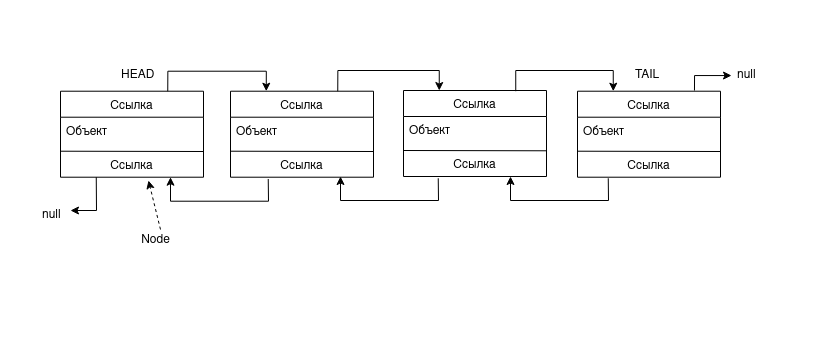
На схеме видно, что это тот же связанный список, однако его элементы содержат ссылки не только на следующий, но и на предыдущий узел. Плюсы и минусы этой структуры, по сравнению с массивами, такие же как и у связанного списка, кроме движения в одном направлении. Однако, стоит сказать, чем отличаются два вида этих связанных списков: очевидный минус “разностороннего” собрата нашего связанного списка в том, что узлы первого требуют больше памяти, ибо хранят в себе 2 ссылки, а не 1. Впрочем, такое устройство списка повышает эффективность некоторых операций, например, удаления. А о возможности передвигаться по списку в двух направлениях было сказано ранее.
Динамический массив
Это улучшенный массив, который умеет изменять свой размер автоматически. Сравним эту структуру данных с нашими связанными списками.
Преимущества
- Есть возможность обратиться к элементу по индексу.
- Элементы хранятся последовательно, они попадают в кэш процессора при обращении к массиву и обрабатываются быстрее.
- Массив занимает меньше памяти, так как с элементами не нужно хранить ссылки на “соседей”.
Недостатки
- Долгие процедуры вставки и удаления. Нам нужно сдвигать все последующие элементы на 1 вправо при вставке, либо влево — при удалении.
- Затратная процедура изменения размера массива.
Стек работает по принципу LIFO (Last In First Out) последний пришёл, первый ушёл. Саму структуру можно представить как стакан, в который кладут объекты. Ниже представлено его схематичное изображение. 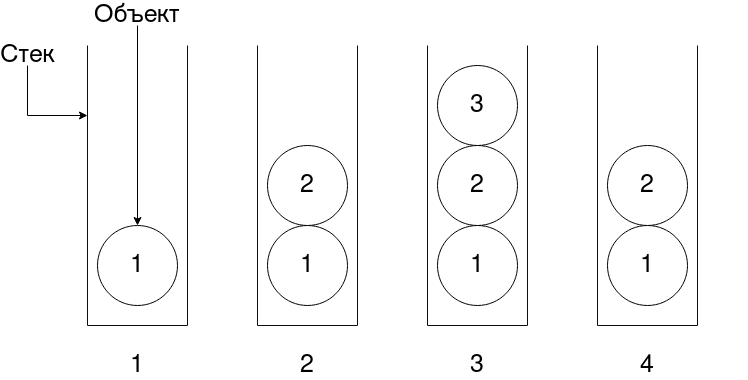 Мы можем положить элемент в стек, либо же вытащить его из стека, также, часто реализуют возможность просто посмотреть что находится наверху, без удаления объекта. На схеме 4 изображения стека, цифра на объекте означает каким по счёту элемент был добавлен в хранилище. На первых 3-х изображениях мы добавляем элементы в стек, а на последнем изображении объект вытаскивается из стека. Как видим, исчез объект, который попал в хранилище последним.
Мы можем положить элемент в стек, либо же вытащить его из стека, также, часто реализуют возможность просто посмотреть что находится наверху, без удаления объекта. На схеме 4 изображения стека, цифра на объекте означает каким по счёту элемент был добавлен в хранилище. На первых 3-х изображениях мы добавляем элементы в стек, а на последнем изображении объект вытаскивается из стека. Как видим, исчез объект, который попал в хранилище последним.
Для хранения стека можно использовать различные структуры данных, например динамический массив или связанный список.
Очередь
Очередь работает так же как и обычная человеческая очередь в магазине или где-то ещё. Здесь соблюдается принцип FIFO (First In First Out) первый пришёл, первый ушёл. Мы можем добавить элемент в один конец очереди и извлечь его из другого конца.
Для хранения очереди, как и для стека, можно использовать различные структуры данных.
Двусторонняя очередь
Можно сказать, что это совмещение очереди и стека. Здесь есть 2 входа и 2 выхода. Значит, что элементы спокойно можно добавлять в начало и конец списка. Точно также мы можем извлекать объекты с любого конца очереди. Скорость работы двусторонней очереди может сильно зависеть от того, что мы выберем хвостом, а что головой. Это справедливо если мы реализуем такую очередь на основе массива (ведь добавление в конец происходит быстро, а вот с началом нужно возиться, передвигая все элементы массива вправо). Использование двунаправленного списка для реализации этой очереди не несёт подобных трудностей, и операции вставки/ удаления крайних элементов выполняются за одинаковое количество времени.
Упорядоченный список
Название говорит само за себя, это список, элементы которого расположены в определённом порядке, например по возрастанию.
Хорошо когда данные сразу отсортированы, потому что процедура сортировки крайне затратна по ресурсам. А чтобы элементы не пришлось сортировать, нам следует использовать упорядоченный список, который сам ставит элемент в нужное место.
Хэш-таблица
Что такое хэш-функция или просто хэш? Если говорить просто, то это некий алгоритм, преобразующий данные. А хэш-таблица — это вместилище данных, преобразованных с помощью хэш-функции. Ниже представлена схема хэш-таблицы.  Есть некий объект (например строка), который мы пропускаем через хэш-функцию (для строки можно складывать коды символов и брать остаток от деления полученной суммы на количество слотов в таблице), она проводит какие-то операции над нашей строкой и выдаёт номер слота, куда её следует поместить.
Есть некий объект (например строка), который мы пропускаем через хэш-функцию (для строки можно складывать коды символов и брать остаток от деления полученной суммы на количество слотов в таблице), она проводит какие-то операции над нашей строкой и выдаёт номер слота, куда её следует поместить.
Что это даёт нам на практике? Скорость: хэширование позволяет очень быстро узнать, где индекс интересующего нас элемента в таблице. Однако не всё так просто, чем больше различных значений необходимо хранить в таблице, и чем меньше в ней слотов, тем выше вероятность возникновения коллизий (ситуация, когда хэш-функция для разных объектов выдаёт один и тот же номер слота). Подбор оптимальной хэш-функции позволяет максимально сократить количество коллизий, но не убрать их. Для решения данной проблемы есть несколько методов разрешения коллизий. Вот пара самых популярных: можно просто ставить элемент, при возникновении коллизии, в следующий свободный слот; А можно сделать так, чтобы в слоте хэш-таблицы хранился список, а когда хэш-функция определяет очередной элемент в занятый слот — добавлять этот объект в список.
Ассоциативный массив
В некоторых кругах известный под именем “Словарь”. Хранит данные в формате ключ-значение. Особенность ключей в том, что ими может быть что угодно и они должны быть уникальны. Для реализации этой структуры данных неплохо подходит хэш-таблица, главное чтобы количество коллизий было в разумных пределах. Берём 2 массива, для ключей и значений, хэш-функция распределяет ключи в первом массиве, а значения во втором массиве записываются в слот, номер которого равен номеру слота соответствующего ключа. В отличие от хэш-таблицы ассоциативный массив не ограничен по размеру, количество ключей для него берётся с гарантированным запасом под конкретную задачу, либо просто используется динамический массив. Кроме хэш-таблицы, для реализации словаря, можно использовать и упорядоченный массив, например, если результатом работы хэш-функции является множество коллизий. Такой массив будет хранить объекты с двумя полями: ключ и значение.
Множество
Это неупорядоченное хранилище данных, элементы которого уникальны. Особенность множества заключается в высокой скорости проверки принадлежности к нему элемента.
Это своего рода хэш-таблица, применяемая когда количество элементов гораздо меньше количества значений. В таких случаях хэш-таблица быстро заполняется и возникает необходимость избавиться от неактуальных элементов, чтобы дать возможность попасть в таблицу новым значениям. Существуют различные схемы вытеснения неактуальных значений, например мы можем просто удалять элемент, который попал в кэш раньше всех.
Получается, что в кэше хранятся самые востребованные элементы, его размещают в наиболее быстрой памяти (оперативная или кэш процессора) чтобы максимально увеличить скорость работы программы.
Заключение
В данной статье рассмотрены базовые структуры данных, изучаемые на 1-м курсе по алгоритмам в школе Сергея Бобровского. Единственная вещь, которую я не затронул тут — фильтр Блюма.
Мою исполнение этих структур данных на языке Java можно посмотреть здесь, наборы методов определены заданиями курса, так же как и некоторые особенности реализации.
Понимание принципов работы и устройства структур данных позволит Вам повысить качество своих программ, ведь правильно подобранная хранилище данных позволяет многократно упростить работу и повысить быстродействие приложения. Также, не обязательно использовать эти структуры по отдельности, есть случаи, когда их комбинация окажется более выгодным решением и повысит эффективность того или иного продукта.
Хеш и кеш в чем раница?
хеш — это контрольная сумма файла. каждый файл имеет свою собственную контрольную сумму, по которой определяется его целостность. чаще всего я сталкивалась с понятием хеш в торрентах. когда добавляешь торрент в закачки, программа проверяет контрольную сумму файла — хеш, и определяет, сколько еще нужно докачать.
а кеш — это область на компьютере (жестком диске или в оперативной памяти), куда система записывает файлы, к которым чаще всего обращается пользователь. тем самым увеличивается быстродействие системы, потому что файл сразу запускается из кеша, а не ищется по всему пространству компьютера. как-то так
Кэш, хэш и няш-меш
UPD0 (2016-07-19 23-31): судя по всему, первая половина моей статьи — успешно изобретённый велосипед. Спасибо хабравчанам за ссылку на спецификацию
Статья ценна не более, чем вольное описание уже придуманной технологии.
Предыстория
Июльский субботний вечер подходил к концу. Нарубив дров на шашлык, я повесил USB-модем на багету, скомандовал sudo wvdial , развернул браузер и обновил вкладку с открытым гитхабом. Вернее, попытался обновить. Скорость не радовала, и в итоге страница-то обновилась, но явно не хватало какого-то из стилевых файлов; и дело было не в блокировке, поскольку аналогичные проблемы я наблюдал и с другими сайтами, и зачастую они решались просто многократным обновлением страницы. Во всём был виноват перегруз 3G-сети.
Стоп! А как же кэш?
Недолгое гугление привело на официальный гугловский мануал. Целиком пересказывать его не буду; скорее всего, дело было в том, что браузер прилежно ждал, когда сервер передаст ETags, а ответ сервера затерялся в переполненных триджунглях.
Через пару дней, возвращаясь душным днём из кафе, я придумал рацпредложение, которое решает эту (и несколько других проблем), которое и излагаю в данной статье.
Суть предложения
Добавить ко всем тэгам для подключения подчинённой статики (стилей, скриптов, изображений) атрибут checksum , который бы хранил хэш (например, SHA-1, как в git) требуемого файла:
Найдя в теле веб-страницы подобный тэг, браузер смотрит, есть ли объект с таким хэшем в кэше, и если есть, то не отправлять никаких запросов вообще: и так понятно, что файл — ровно тот, который требуется. Файлы в кэше браузера лучше сразу хранить с именами, соответствующими их хэшам, как это делает тот же git.
Обратная совместимость предлагаемого решения очевидна.
Какие проблемы это решает?
Пресловутая угадайка: актуален ли файл в кэше?
- Больше не нужно отправлять запрос и сличать полученные ETags.
- Даже если файл в кэше вроде как устарел, но хэш совпадает — его можно смело использовать.
- Чистка кэша как средство решения проблем частично теряет актуальность.
Дилемма: jQuery со своего домена или с CDN?
Владельцам малых сайтов часто приходится выбирать: либо подключать jQuery и/или подобные ей библиотеки с CDN (гугловского, например), или со своего домена.
В первом случае уменьшается время загрузки сайта (в том числе первичной, т.е. при первом заходе посетителя на сайт) за счёт того, что файл с серверов Гугла с большой долей вероятности уже есть в кэше браузера. Но, например, разработчики WordPress придерживаются второго варианта, ставя во главу угла автономность. И в условиях, когда CDN падают, блокируются и т.д., их можно понять.
Теперь от такой проблемы можно будет избавиться навсегда: не всё ли равно, откуда получен файл, если его содержимое — это ровно то, что нужно html-странице, и она это удостоверяет? Можно смело указывать свой домен, и если библиотека есть в кэше (неважно, загруженная с этого сайта, другого «малого» сайта или из какого-нибудь CDN) — она подхватится.
Смешанный HTTPS/HTTP-контент
Одна из причин запрета загрузки HTTP-ресурсов на HTTPS-страницах — возможность подмены HTTP-контента. Теперь это больше не преграда: браузер может получить требуемый контент и сверить его хэш с хэшем, переданным по HTTP. Отмена запрета на смешанный контент (при наличии и совпадении хэша) позволит ускорить распространение HTTPS.
Косвенное определение истории по времени загрузки статики
Известно, что владелец некоторого сайта evilsite.org может (с некоторой долей вероятности) определить, был ли посетитель на другом сайте goodsite.org , запросив, например, изображение goodsite.org/favicon.ico . Если время загрузки иконки ничтожно мало — то она в кэше, следовательно, посетитель был на сайте goodsite.org . Теперь эта атака усложнится: околонулевое время отклика будет лишь обозначать, что посетитель был на сайте с таким же фавиконом. Это, конечно, не решает проблему целиком, но всё же несколько усложняет жизнь определяющему.
На что это не влияет?
- На html-страницы
- На изображения, стили и скрипты, открываемые по непосредственной ссылке, а не служащие вспомогательными элементами страницы.
- На изображения, стили и скрипты, которые не предполагаются неизменными, например, когда подключается самая новая версия некоторой библиотеки с CDN этой библиотеки.
Идеология
Как обычно (математик я, что уж тут поделать) сформулируем аксиомы, которые вкладываются в предложение:
- Все передаваемые файлы делятся на главные (в основном html-страницы) и подчинённые (скрипты, изображения, стили и т.д.).
В идеологии, заложенной в стандарты HTTP-кэширования, все файлы равноправны. Это, конечно, толерантно, но не отвечает современным реалиям. - Неважно, откуда получен подчинённый файл. Важно, что его содержимое удовлетворяет нужды главного.
В существующей идеологии даже сама аббревиатура URI — Uniform Resource Identifier — предполагает, что идентификатором ресурса является его адрес в сети. Но, увы, для подчинённых файлов это несколько не соответствует действительности.
Перспективы
Обещанный няш-меш
Зная хэш требуемого вспомогательно файла, можно почти смело запрашивать его у кого угодно; основная опасность: если опрашиваемый узел действительно имеет требуемый файл, то он знает его содержимое и, скорее всего, как минимум один URI-адрес, по которому требуемый файл может (или мог) быть получен. Имеем два варианта использования предлагаемой технологии с учётом этой угрозы с целью плавного подхода к няш-меш сети:
Доверенные устройства
Например, в офисе работают программисты, ЭВМ которых объединены в локальную сеть. Программист Вася приходит рано утром, открывает гитхаб и получает в кэш стили от нового дизайна, который выкатили ночью (у нас — ночь, там — день). Когда в офис приходит программист Петя и тоже загружает html-код гитхабовской странички, его ЭВМ спрашивает у всех ЭВМ в сети: «А нет ли у вас файла с таким-то хэшем?» «Лови!» — отвечает Васина ЭВМ, экономя тем самым трафик.
Потом наступает перерыв, Вася и Петя лезут смотреть котиков и пересылают фотографии друг другу. Но каждый котик скачивается через канал офиса только один раз.
Анонимный разделяемый кэш
Аня едет в трамвае с работы и читает новости… например, на Яндекс-Новостях. Встретив очередной тэг <img> , Анин телефон со случайного MAC-адреса спрашивает всех, кого видит: «Ребят, а ни у кого нет файла с таким-то хэшем?». Если ответ получен в разумное время — профит, Аня сэкономила недешёвый мобильный трафик. Важно почаще менять MAC-адрес на случайный да не «орать», когда в поле видимости слишком мало узлов и спрашивающего можно идентифицировать визуально.
Разумность времени ответа определяется исходя из стоимости трафика.
Дальнейший переход к няш-мешу
Фотография в соцсети может быть представлена как блоб, содержаший хэш и адрес собственно изображения (возможно, в нескольких различных размерах), а также список комментариев и лайков. Этот блоб тоже можно рассматривать как вспомогательный файл, кэшировать и передавать друг другу.
Более того, альбом фотографий тоже легко превращается в блоб: список хэшей изображений + список хэшей блобов-фотографий (первое нужно, чтобы при добавлении лайка/комментария показывать фотографии сразу, а метаинформацию — по мере её получения).
Останется только реализовать электронную подпись и поля вида «замещает блоб такой-то» — и готова няш-меш-социалочка.
Компактизация хэша
В идеале при записи хэша следует использовать не шестнадцатеричную систему счисления, а систему с бОльшим основанием (раз уж мы взялись экономить трафик). Ещё одна идея — атрибут magnet , содержащий magnet-ссылку. Дёшево, сердито, стандартизировано и позволяет указывать также несколько классических адресов источников, что бывает немаловажно в случае ковровых блокировок и в случаях, когда браузеру известно, что трафик к различным серверам тарифицируется по-разному.
Поведение при несовпадении
Возможна ситуация, когда хэш полученного файла не совпал с требуемым. В таком случае разумно бы было предусмотреть мета-тэги, указывающие браузеру, следует ли такой файл использовать (по умолчанию — нет) и следует ли сообщить об инциденте серверу (по умолчанию — нет).
Файлы-альтернативы
В некоторых случаях можно использовать любой из нескольких файлов с разными хэшами. Например, на сайте используется минифицированная jQuery, но если в кэше браузера есть неминифицированная — что мешает использовать её?
Превентивное кэширование
Многие устройства работают в двух режимах: когда интернет условно-безлимитен (например, мобильный телефон в вай-фай сети) и когда интернет ограничен (лимит по трафику или узкий канал). Браузер или расширение к нему может, пользуясь безлимитным подключением, заранее скачивать популярные библиотеки (наподобие jQuery и плагинов к ней), также по мере необходимости их обновлять. Это ли не мечта многих, чтобы jQuery была включена в браузер?
Заключение
Выдвигаемое рацпредложение актуально, так как борьба за оптимизацию загрузки сайтов идёт полным ходом. Более всего выиграют малые и средние сайты за счёт разделяемых библиотек (и, может быть, некоторых часто используемых изображений) в кэше. Уменьшится потребление трафика мобильными устройствами, что важно с учётом ограниченной пропускной способности каналов сотового интернета. Крупные сайты также могут уменьшить нагрузку на свои серверы в случае, если будут внедрены mesh-технологии.
Таким образом, поддержка предлагаемой технологии выгодна и вебмастерам, чьи сайты будут грузиться быстрее, и производителям браузеров, которые тоже будут быстрее отображать страницы, и провайдерам, у которых уменьшится потребление полосы (пусть и не столь значительно, но от провайдеров активных действий и не требуется).
Хеширование
Хеширование — это преобразование информации с помощью особых математических формул. В результате возникает хеш — отображение данных в виде короткой строки, в идеале — уникальной для каждого набора информации. Размер строки может быть одинаковым для информации разного объема.

«IT-специалист с нуля» наш лучший курс для старта в IT
Что такое хеш
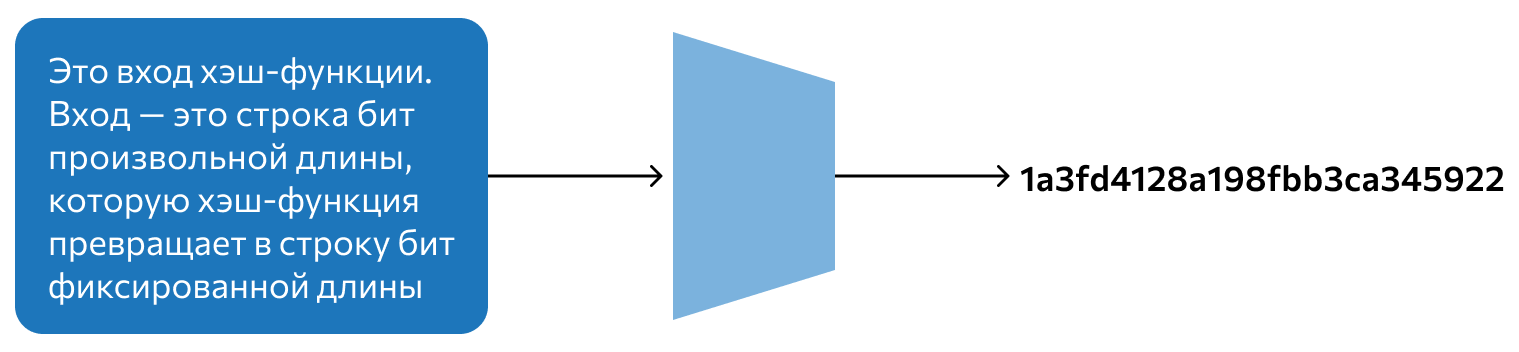 Как устроено хеширование
Как устроено хеширование
Хеш — это не закодированная исходная информация. Это скорее уникальная метка, которая генерируется для каждого набора данных индивидуально. Если захешировать большую книгу и одно слово, получатся хеши одинаковой длины. А если изменить в слове одну букву и снова захешировать полученную строку, новый хеш будет совершенно другим, там не окажется участков, которые повторяли бы предыдущий.
Хеш-функция — это математический алгоритм, по которому хешируется информация. Его название тоже иногда сокращают как «хеш». Хеш-функций существует очень много, они различаются методами вычислений, назначением, надежностью и другими параметрами.
Попробуйте 9 профессий за 2 месяца и выберите подходящую вам

Кто работает с хешированием
- IT-специалисты, разработки которых хранят чувствительную конфиденциальную информацию. Например, в веб-разработке хеши обычно нужны для проверки паролей. Вместо них на сервере хранятся хеши, а когда пользователь вводит пароль, тот автоматически хешируется, и хеш сравнивается с сохраненным на сервере.
- Разработчики, имеющие дело со сложными структурами данных, такими как ассоциативные массивы и хеш-таблицы.
- Люди, которые имеют дело с криптовалютой. В этой сфере активно используется хеширование как удобный способ проверки подлинности данных. На алгоритмах хеширования во многом построен блокчейн.
- Этичные хакеры и специалисты по информационной безопасности для обеспечения конфиденциальности данных или, наоборот, для проверки той или иной информации. Например, конкретный вирус можно распознать по характерному хешу.
Для чего нужно хеширование
Основное назначение хеширования — проверка информации. Эта задача важна в огромном количестве случаев: от проверки паролей на сайте до сложных вычислений в блокчейне. Так как хеш — это уникальный код определенного набора данных, по нему можно понять, соответствует ли информация ожидаемой. Поэтому программа может хранить хеши вместо образца данных для сравнения. Это может быть нужно для защиты чувствительных сведений или экономии места.
Вот несколько примеров:
- вместо паролей на сервере хранятся хеши паролей;
- антивирус хранит в базе хеши вирусов, а не образцы самих программ;
- электронная подпись использует хеш для верификации;
- информация о транзакциях криптовалюты хранится в виде кешей;
- коммиты в Git идентифицируются по хешу (подробнее про Git и коммиты можно прочесть в нашей статье).
Среди других, менее распространенных примеров использования — поиск дубликатов в больших массивах информации, генерация ID и построение особых структур данных. Это, например, хеш-таблицы — в них идентификатором элемента является его хеш, и он же определяет расположение элемента в таблице.
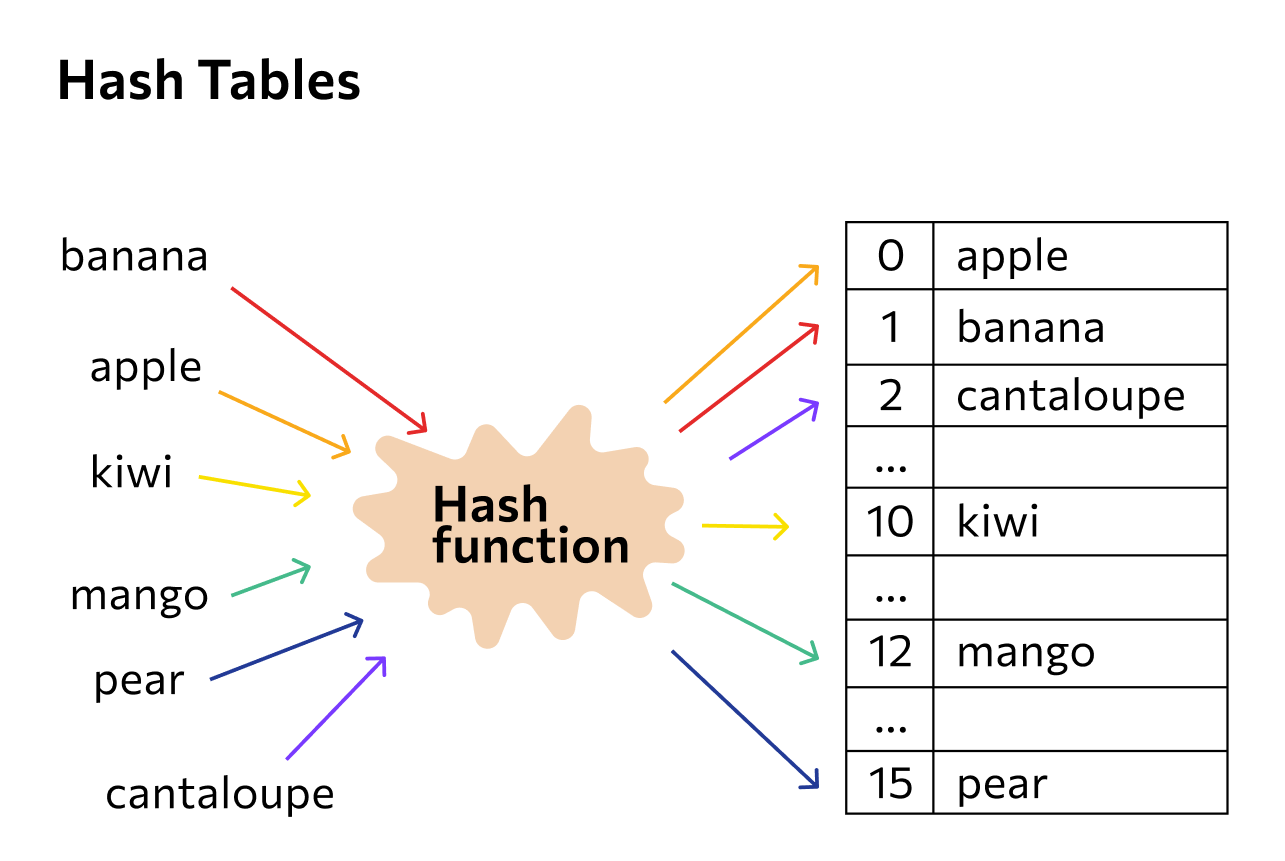
Как работает хеш-функция
Возможных преобразований для получения хеша бесконечное количество. Это могут быть формулы на основе умножения, деления и других операций, алгоритмы разного уровня сложности. Но если хеш применяется для защиты данных, его функция должна быть криптографической — у таких хеш-функций есть определенные свойства. Именно криптографические хеш-функции используются, например, при хранении паролей.
Если говорить о криптографической хеш-функции, то она чаще всего работает в несколько шагов. Данные разбиваются на части и проходят через сжимающую функцию, которая преобразовывает информацию в меньшее количество бит. Функция должна быть криптостойкой — такой, результат которой практически невозможно вскрыть.
А вот хеш-функции для более простых случаев, например построения таблиц, не обязаны быть криптографическими. Там преобразования могут быть проще.

Курс для новичков «IT-специалист
с нуля» – разберемся, какая профессия вам подходит, и поможем вам ее освоить
Свойства криптографических хеш-функций
Необратимость. Из хеша нельзя получить исходные данные даже теоретически. Слишком много информации отбрасывается в процессе; это не зашифровка информации.
Детерминированность. Если подать хеш-функции одинаковые данные, то и хеш у них будет одинаковым. Именно это свойство позволяет использовать хеши для проверки подлинности информации.
Уникальность. Идеальная хеш-функция выдает стопроцентно уникальный результат для каждого возможного набора данных. В реальности такое невозможно, и иногда случаются коллизии — одинаковые хеши для разных сведений. Но существующие хеш-функции достаточно сложны, поэтому вероятность коллизии сводится к минимуму.
Разнообразие. Даже если два набора информации различаются одним-двумя символами, их хеши будут кардинально разными. У них не будет общих блоков, по ним невозможно будет понять, что исходные данные схожи.
Высокая скорость генерации. Это в целом свойство любых хешей: в отличие от зашифрованных версий файлов, они генерируются быстро, даже если входной массив данных большой.
Взламывайте ПО безнаказанно и за оплату

Безопасность криптографической хеш-функции
Цель использования хешей — обеспечить безопасность пользователей. Идентификация или проверка подлинности данных нужны, чтобы никто не мог воспользоваться чувствительной информацией в своих целях. Поэтому специалисты пользуются именно криптографическими хеш-функциями. Они должны быть безопасными — так, чтобы никто не мог взломать их.
Идеальная криптографическая хеш-функция полностью отвечает перечисленным ниже требованиям. Реальные не могут ответить им на 100%, поэтому задача их создателей — максимально приблизиться к нужным свойствам.
Стойкость к коллизиям. Выше мы писали, что коллизия — явление, когда у двух разных наборов данных получается одинаковый хеш. Это небезопасно, потому что так злоумышленник сможет подменить верную информацию неверной. Поэтому коллизий стремятся максимально избегать.
Современные криптографические хеш-функции не полностью устойчивы к коллизиям. Но так как они очень сложные, для поиска коллизии нужно огромное количество вычислений и много времени — годы или даже столетия. Задача такого поиска становится практически невыполнимой.
Стойкость к восстановлению данных. Частично это означает все ту же необратимость, о которой мы писали выше. Но восстановить данные в теории можно не только с помощью обратной функции — еще есть метод подбора. Стойкость к восстановлению данных подразумевает, что, даже если злоумышленник будет очень долго подбирать возможные комбинации, он никогда не сможет получить исходный массив информации.
Это требование выполняется для современных функций. Информации в мире настолько много, что полный перебор всех возможных комбинаций занял бы бесконечно большое количество времени.
Устойчивость к поиску первого и второго прообраза. Первый прообраз — как раз возможность найти обратную функцию. Такой возможности нет, ведь криптографическая хеш-функция необратима. Этот пункт пересекается с требованием стойкости к восстановлению данных.
Второй прообраз — почти то же самое, что нахождение коллизии. Разница только в том, что в случае со вторым прообразом ищущий знает и хеш, и исходные данные, а при поиске коллизии — только хеш. Хеш-функция, неустойчивая к поиску второго прообраза, уязвима: если злоумышленник будет знать исходные данные, он сможет подменить информацию.
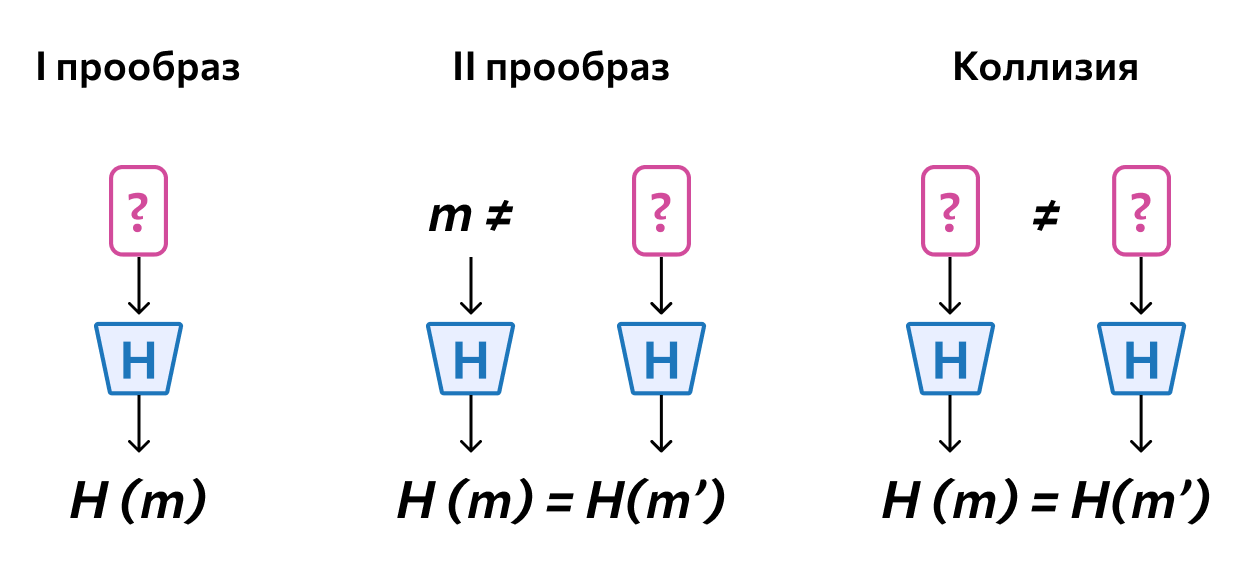 Прообразы и коллизия
Прообразы и коллизия
Криптографические хеш-функции устойчивы к поиску второго прообраза потому же, почему они считаются стойкими к коллизиям. Вычисления для нахождения таких данных слишком сложные и длительные, чтобы задача была реальной.
Наш лучший курс для старта в IT. За 2 месяца вы пробуете себя в девяти разных профессиях: мобильной и веб-разработке, тестировании, аналитике и даже Data Science — выберите подходящую и сразу освойте ее.