Что такое веб-архив и как им пользоваться
Веб-архив — это проект web.archive.org, на котором хранятся разные версии всех сайтов с момента их создания при условии, что нет запрета на сохранение ресурса. Благодаря наличию сохраненных копий в веб-архиве, доступно восстановление сайта даже при отсутствии резервной копии. Также в веб-архиве можно найти интересный контент из закрытых сайтов конкурентов, который активно используют создатели PBN-сеток сайтов.
Что такое веб-архив
Веб-архив сайтов позиционируется как своеобразная бесплатная машина времени, позволяющая вернуться на месяцы или годы назад, чтобы увидеть, как выглядел ресурс на тот момент. При этом у каждого сайта сохраняются многочисленные версии от разных дат, которые зависят от посещений проекта краулерами веб-архива. У популярных сайтов может сохраняться тысячи версий, которые обновлялись ежедневно множество раз на протяжении всего периода существования проекта:
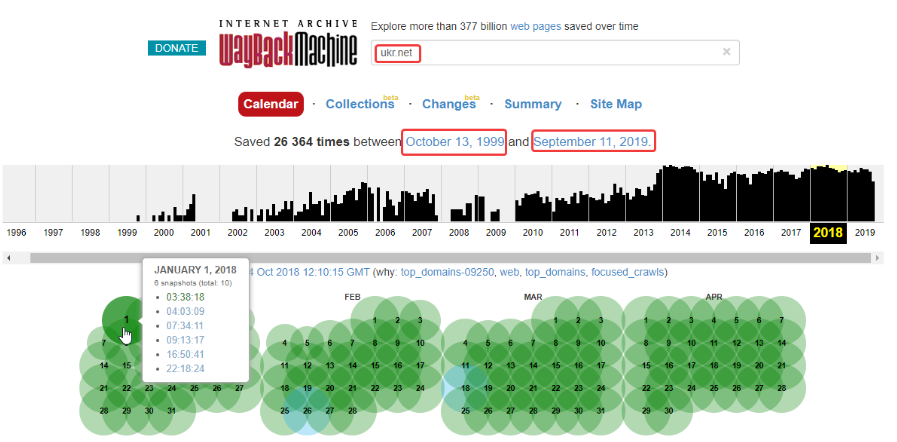
Веб-архив основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
Как использовать архив
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
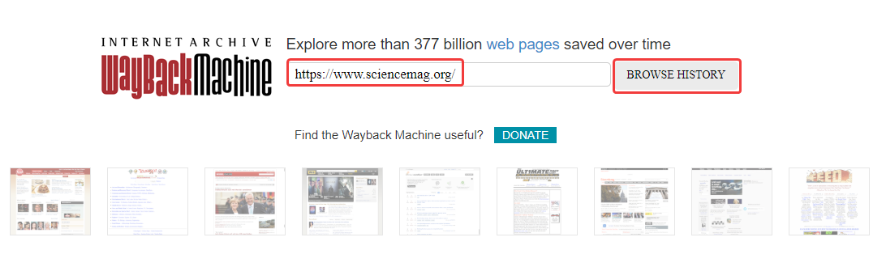
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
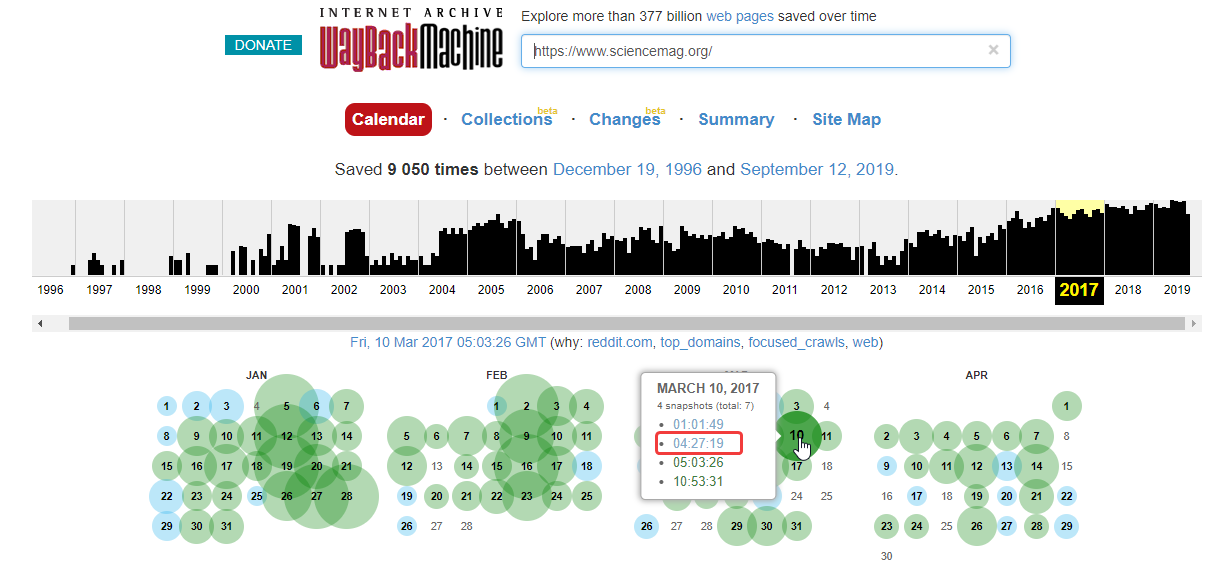
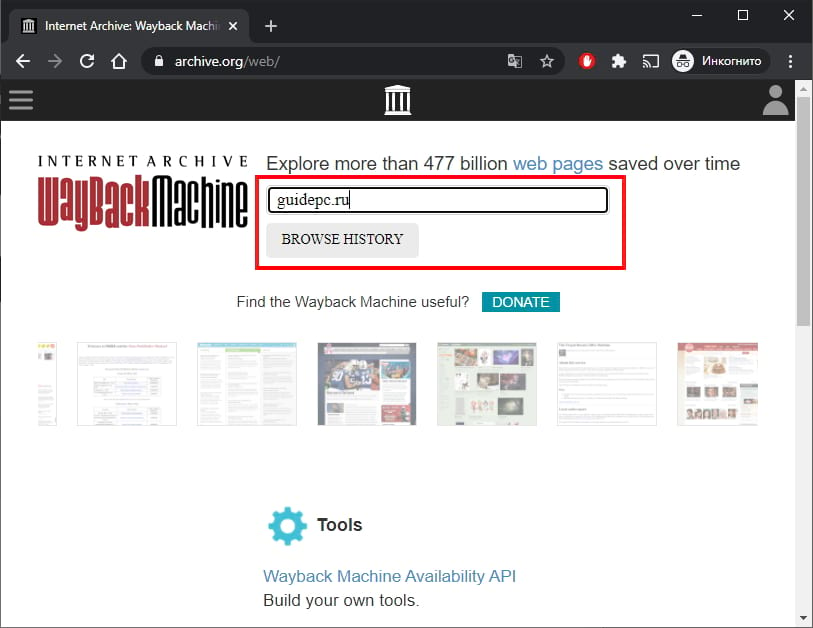
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
Как добавить современную версию сайта в веб-архив
Для уверенности в том, что все нужные версии собственного проекта будут сохранены в веб-архиве, желательно самостоятельно инициировать сканирование сайта. Для этого введем в разделе «Save Page Now» домен сайта и нажмем «Save page»:
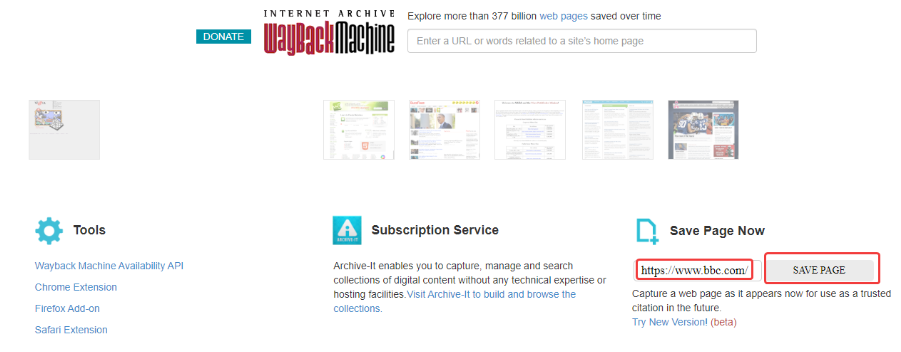
После этого в архив будет добавлена текущая версия сайта. На всякий случай повторяйте подобную процедуру перед всеми существенными изменениями сайта и после их осуществления.
Как запретить добавление сайта в веб-архив
Чтобы сайт не был доступен в веб-архиве, пропишите запрет в файле robots.txt. Для этого нужно зайти в корневой каталог сайта на панели управления хостинг-провайдера и выбрать редактирование данного файла:
Запрет устанавливается с помощью такого кода:
После этого удалятся существующие версии проекта, а также не будет осуществляться копирование сайта в архив пока домен функционирует и в файле robots.txt присутствуют данные настройки. Когда закончится регистрация доменного имени старые версии сайта вновь станут доступны в веб-архиве.
Восстановление сайта из веб архива
Восстановить удаленный либо взломанный хакерами сайт поможет веб-архив. Восстановление каждой отдельной HTML-страницы проекта слишком трудоемкий процесс, поэтому предпочтительнее использовать специальные программы для парсинга WEB-архива.
Как парсить веб-архив с помощью Robotools
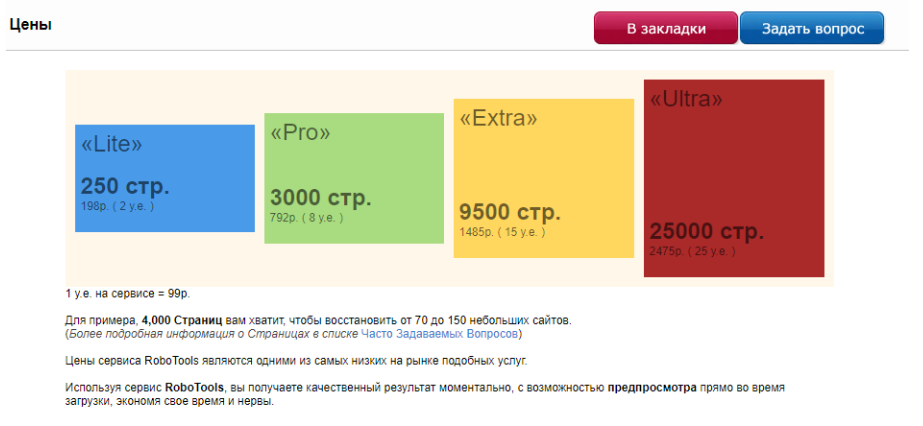
Для скачивания сайта с помощью данного сервиса необходимо выбрать подходящий тариф в зависимости от количества веб-страниц на проекте:
Протестировать работу сервиса можно в демо-версии, после регистрации будет доступно 25 страниц бесплатно:
Перейдем в раздел «Мои задачи», укажем домен, на котором ранее функционировал нужный сайт и нажмем «Запуск»:
Затем выбираем «Восстановить домен или снимок из веб-архива»:
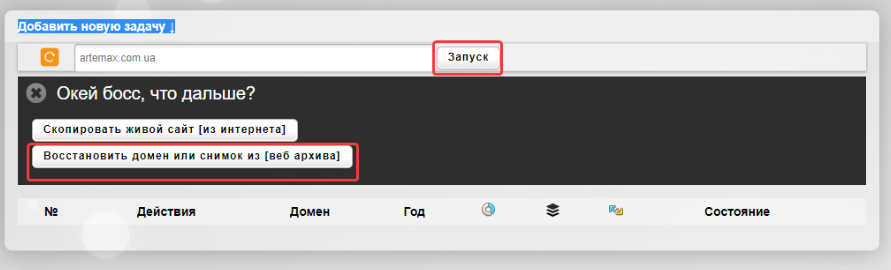
После этого выбираем нужную дату, количество страниц, действия с внешними ссылками в статьях и нажимаем «Начать процесс восстановления»:
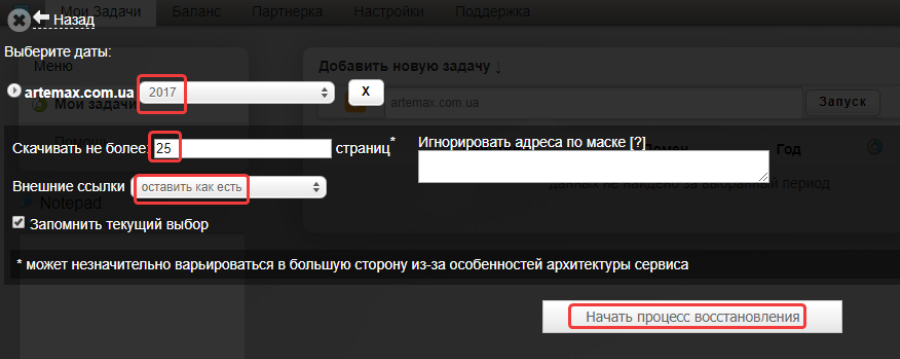
После завершения задачи нажимаем на кнопку для скачивания архива с веб-страницами:
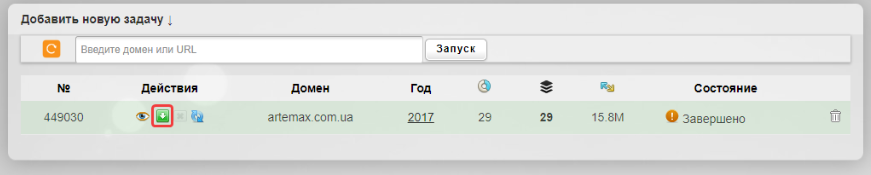
Затем нажимаем «Все ОК, собрать ZIP-архив»:
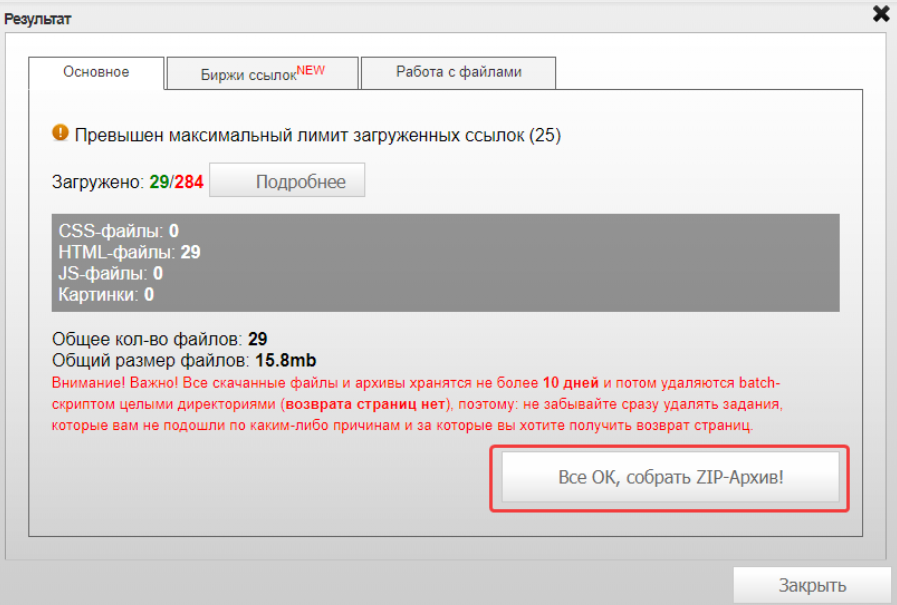
После этого нажимаем «Скачать архив»:
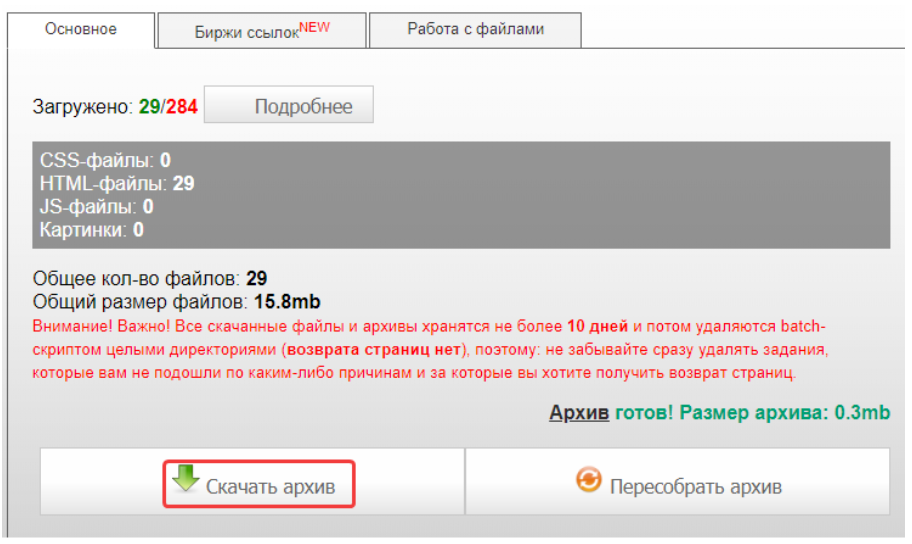
В данном примере рассматривалось восстановление сайта на WordPress, получен архив с такими файлами:
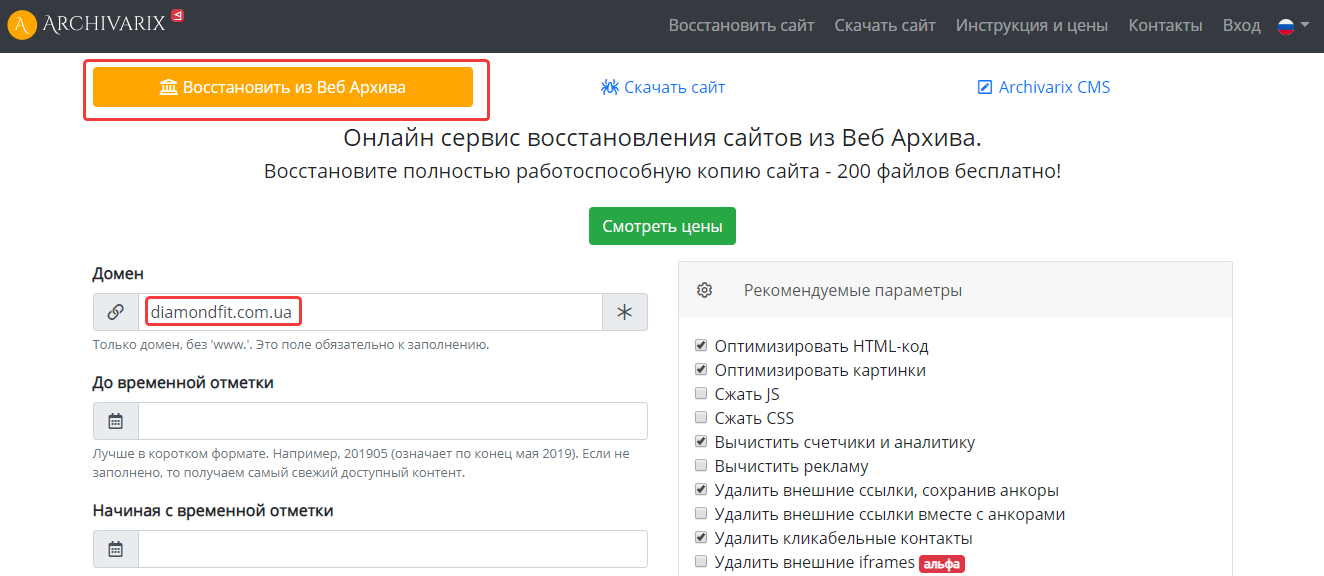
Как скачать сайт из веб-архива с помощью Archivarix
Этот сервис также помогает восстановить старые версии сайтов из веб-архива. Цены зависят от количества файлов на проекте. Начнем работу с выбора раздела «Восстановить из веб-архива». Укажем домен и при желании установим временной диапазон, в правой колонке отметим дополнительные параметры восстанавливаемого проекта:
Затем укажем электронный адрес и нажмем «Восстановить»:
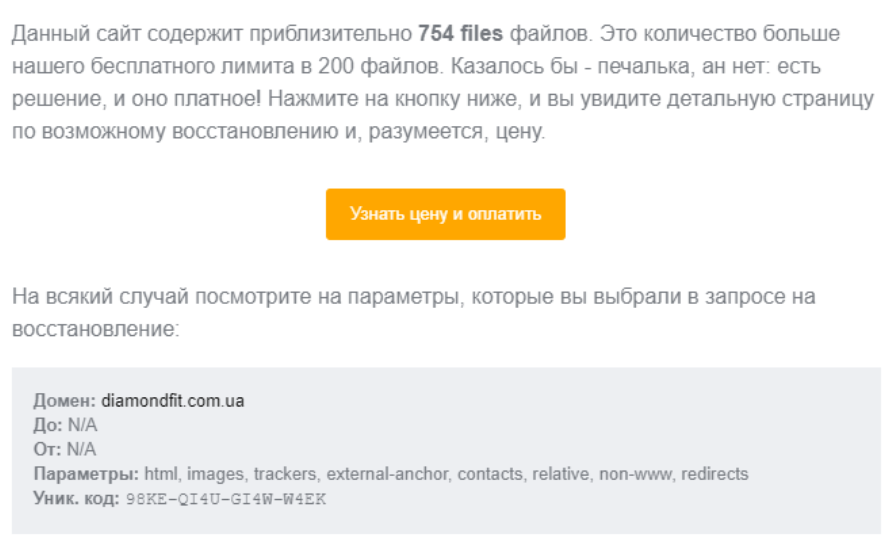
Если сайт содержит более 200 файлов, придет уведомление на почту с предложением оплатить восстановление проекта:
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Запомнить
- Веб-архив — масштабный бесплатный проект, созданный для сохранения всего контента, представленного в интернете, даже после его удаления на исходном сайте.
- Веб-архив полезен для анализа сайтов клиентов и конкурентов, отслеживания изменений на собственном проекте, проверки доменов перед покупкой.
- Используя данные веб-архива, полученные с помощью онлайн-сервисов, доступно восстановление сайта без бэкапа.
- В веб-архиве много контента, в том числе уникальные статьи почти на любую тематику.
Закончил факультет кибернетики. Работал интернет-маркетологом. Не по наслышке знаком с SEO, PPC, таргетингом, ремаркетингом и продвижением сайтов — в течение нескольких лет практиковал на фрилансе. В портфолио есть успешные кейсы. Пробовал создать собственное агентство, но прогорел и решил поменять сферу деятельности. Далеко из профессии не ушел — использовал свои знания и опыт в копирайтинге. С 2016 года работаю редактором и автором текстов в Netpeak Journal.
Как узнать историю сайта и восстановить его из веб-архива

История сайтов полезна вебмастерам при покупке доменов, чтобы вычислить возраст, узнать важные показатели и отделить хорошие от плохих. Ведь фильтры и баны в прошлом напрямую влияют на продвижение сайта в будущем. Поэтому стоит покупать новые домены либо домены с положительной историей.
1. Зачем нужна история сайта
Хронография домена зачастую выдаёт информацию о нём с момента создания. Виртуальные архивы сайтов также дают возможность узнать:
- сколько времени существует домен;
- как выглядел сайт раньше, вплоть до конкретной даты;
- тематику сайта в прошлом;
- наличие банов, фильтров, санкций в прошлом, действуют ли они сейчас;
- количество владельцев ресурса;
- другие домены в пределах сервера, на котором был сайт.
При помощи архивных данных, которые хранятся в интернет-архивах, можно восстановить информацию, которая была утеряна, и посмотреть, как сайт выглядел раньше. Например, если при обновлении баз данных либо смене шаблона сайт перестал работать, можно восстановить сайт из веб-архива по дате и скопировать оттуда старые тексты.
Бывает и так: анализ трафика показал, что при прошлом дизайне сайт приносил больше прибыли. Сравнение текущей и прошлой версий одного ресурса позволяет сделать соответствующие выводы и улучшить работу.
В отличие от старых доменов, новые всегда обладают чистой историей, ведь у них не было владельцев, и они не были зарегистрированы как сайты. Такие домены покупают, не боясь столкнуться с фильтрами и другими проблемами. Однако многие вебмастера предпочитают покупать готовые сайты с рук или на аукционах. Причина здесь одна: старый домен с хорошей историей легче продвинуть в поиске, чем начинать оптимизацию с чистого листа.
При покупке старого сайта нужно тщательно проверять его прошлое. Важно, чтобы на сайте не было ворованного контента, запрещённых тематик и банов по причине любых нарушений.
Чтобы убедиться, что вы покупаете не кота в мешке, вы можете пройтись по нашему чеклисту «Как проверить сайт перед покупкой».
2. Принципы работы веб-архивов
Веб-архивы время от времени посещают открытые к доступу сайты. При одном таком посещении автоматически создаются точные копии страниц, которые сохраняются на сервере архива. Под каждой копией отмечается дата. Дальше любой пользователь может восстановить нужную версию сайта через календарь.
2.1. Инструменты для проверки истории сайта, и как ими пользоваться
2.1.1. Webarchive
Самый крупный ресурс, на котором хранится история большинства сайтов, — Webarchive. Иногда этот сервис называют машиной времени сайтов или Wayback Machine. Здесь можно посмотреть даже историю тех ресурсов, которые давно прекратили существование.

Чтобы проверить состояние домена, нужно ввести его в строку поиска и нажать Enter. Сервис выдаст информацию о сайте с момента его первой регистрации. В нижней части страницы отображается календарь с кликабельными датами. После нажатия на число архив покажет версию сайта, которая была актуальна в тот день.
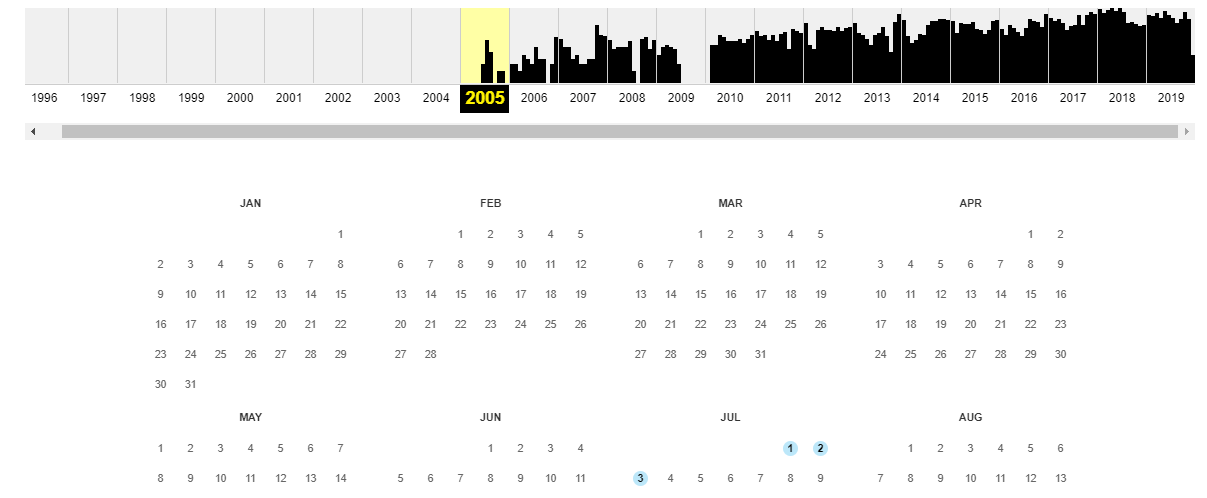
Синим цветом отмечены даты сохранения копий страниц сайта, зелёным — версии с редиректами. С помощью стрелок вверху можно проследить историю изменения сайта по хронологии.

Бывает, что история сайта недоступна. Этому есть несколько причин:
- в файле robots.txt есть запрет на архивацию данных,
- владелец домена удалил сохраненные версии сайта,
- сайт был закрыт из-за нарушений прав собственности.
Чтобы запретить архивацию сайта, можно прописать в robots.txt директиву на запрет сохранения копий:
После этого никто не сумеет восстановить страницы вашего сайта в будущем. Но и вы сами не сможете сделать это, если потребуется.
Если в Webarchive нет интересующего вас сайта, вы можете сами добавить его в сервис, сохранив актуальную копию любой страницы сайта. Для этого нужно ввести её текущий адрес и нажать «Save page».
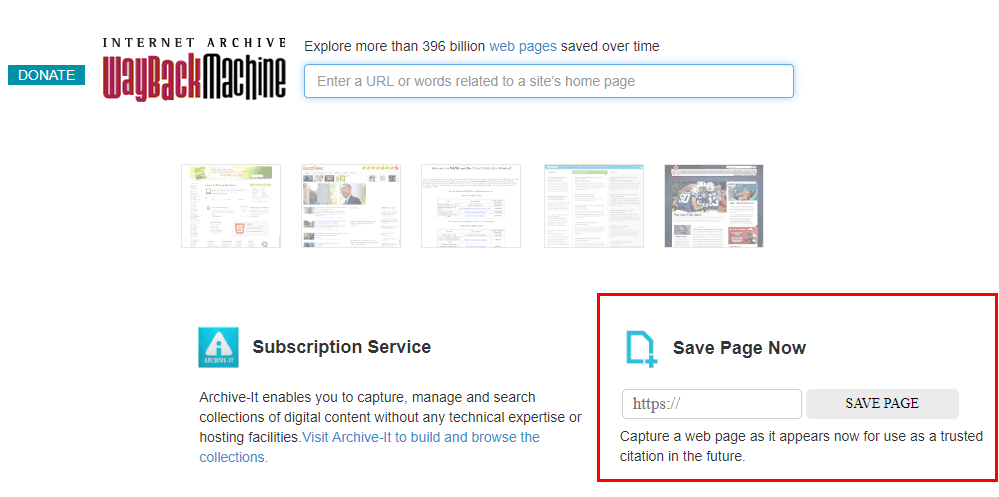
Этот сервис также может быть полезен, когда необходимо восстановить неработающий сайт через инструмент RoboTools c большой базой уникальных текстов. Например, домен выставлен на продажу, а в его истории сохранены страницы с хорошими текстами. Так как сайта уже не существует — его страницы не индексируются. Поэтому старые тексты можно использовать для наполнения нового проекта.
2.1.2. Whois
Еще один инструмент для проверки доменных имён — Whois. С его помощью можно узнать:
- занят ли домен,
- был ли он забанен,
- количество регистраций,
- название и локацию серверов,
- дату основания и другую информацию.
Для этого нужно ввести URL в строку поиска.
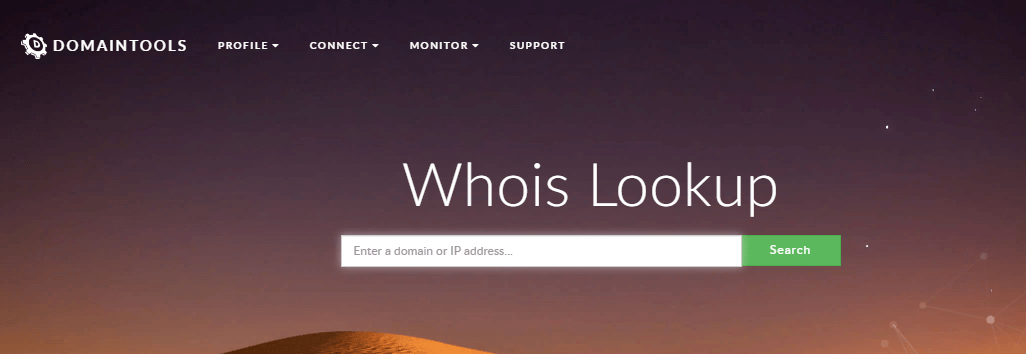
После анализа сайта при нажатии на стрелку в разделе «Dates» открывается более подробная информация о домене.

- Загрузите список доменов в программу.
- Отметьте нужные пункты из чекбоксов «Wayback Machine» и «Whois».
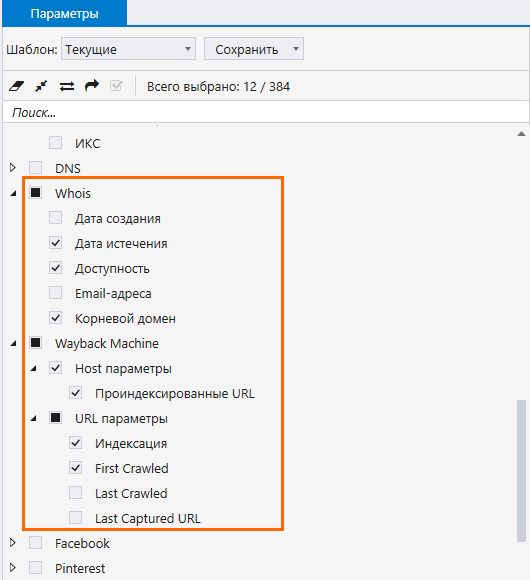
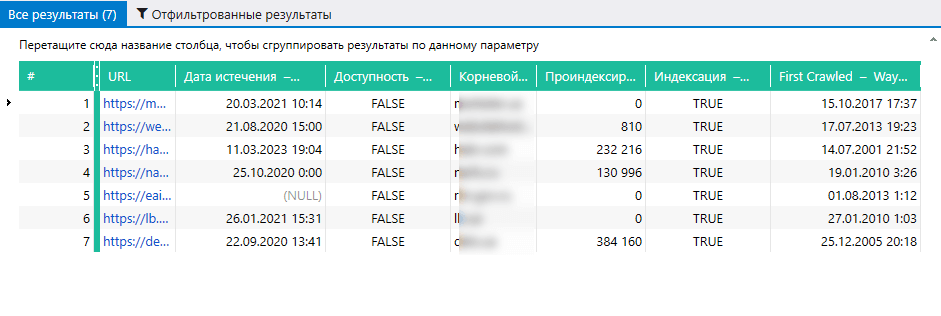
Тянуть данные из сервисов и делать массовую проверку URL вы можете даже в бесплатной версии Netpeak Checker без ограничений по времени и количеству URL, в которой также доступно много других базовых функций.
Чтобы начать пользоваться бесплатным Netpeak Checker, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.
3. Как восстановить сайт из веб-архива
Для восстановления сайта из веб-архива используется сервис Аrchivarix.
После введения информации появляется уведомление с подтверждением. Здесь же виден скриншот сайта и данные о нём. Параллельно на почту приходит письмо с архивными данными для восстановления. Остаётся загрузить эти файлы на сервер и проверить работоспособность сайта.
Подводим итоги
Посмотреть историю сайта можно при помощи веб-архивов — сервисов, которые создают копии страниц в разные периоды времени. Даже если сайт прекращает существование, информация о его предыдущих версиях может оставаться в открытом доступе.
Самым популярным сайтом для просмотра и восстановления истории считается Wayback Machine. В нём хранятся все данные о домене с момента его создания. Если нажать на определенную дату в календаре, можно посмотреть, как выглядел сайт в тот день.
Дополнительно вы можете сохранить текущую версию сайта, восстановить неработающий домен и проверить, был ли он когда-то использован. Также узнать информацию о сайте можно при помощи сервисов Whois, Whoishistory и аналогов.
А вы пользуетесь этими сервисами? Для каких задач? Поделитесь в комментариях 😊
Как просматривать старые версии сайтов

W ayback Machine — это онлайн-сервис, который сканирует веб-сайты, делая снимки сайтов в определенный момент времени. Используя Wayback Machine, Вы можете увидеть, как выглядел почти любой сайт на протяжении всей его жизни.
Веб-сайты часто меняются, как и законы, регулирующие эти веб-сайты. Будь то потеря данных, новая цензура контента или просто любопытство, Wayback Machine позволяет Вам видеть контент, которого больше нет в сети. Wayback Machine также может использоваться для устранения неполадок.
Примечание: Некоторые сайты могут не отображаться из-за того, что они защищены паролем, заблокированы файлом robots.txt или были недоступны по какой-либо другой причине.
Перейдите на официальный сайт Internet Archive и введите URL-адрес сайта, который Вы хотите просмотреть, в адресной строке Wayback Machine. После ввода нажмите «Browse History».
На следующей странице Вы увидите временную шкалу, содержащую снимки указанного веб-сайта. Также есть примечание о количестве снимков веб-сайта между двумя датами.
Выберите год, который хотите просмотреть.
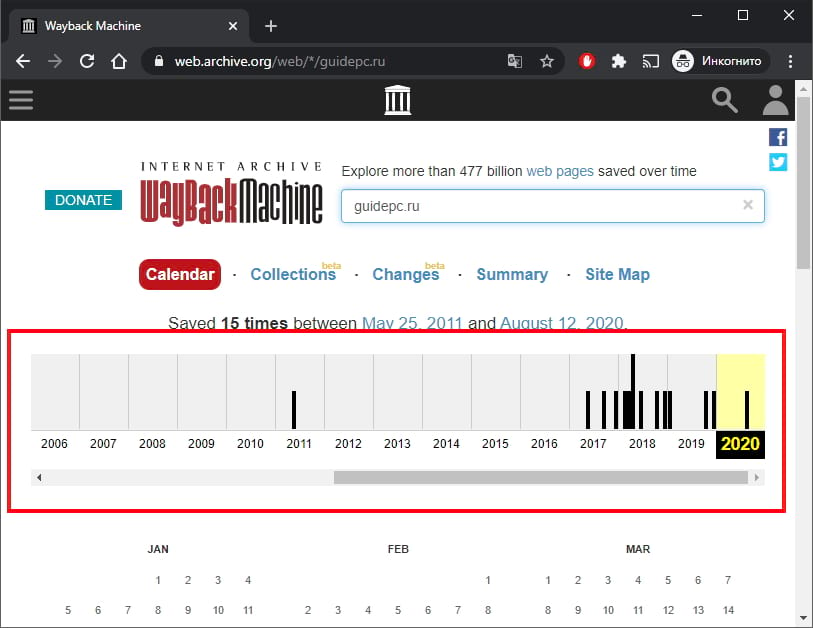
Вы увидите календарь на выбранный год. В определенные даты в течение года Вы заметите, что они выделены определенным цветом. Вот что они означают:
- Без цвета: сайт не был сохранен в этот день.
- Синий: веб-сайт был успешно сохранен в этот день.
- Зеленый: указывает на перенаправление (3xx).
Вы также заметите, что одни круги больше других. Это означает, что на веб-сайте есть несколько снимков для этой конкретной даты. Обратите внимание, что это не отражает количество обновлений сайта.
Выберите дату и время, которые Вы хотите просмотреть, наведя курсор на дату и выбрав снимок во всплывающем меню.
Как найти архивные копии сайтов интернета или машина времени для сайтов
Существует настоящая, реальная машина времени, в которой можно ненадолго вернуться в прошлое и увидеть, например, как выглядел тот или иной сайт несколько лет назад. Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.
Во-первых, это просто интересно! Из чистого любопытства и от избытка свободного времени можно посмотреть, как выглядел любимый, популярный ресурс на заре его рождения.
Во-вторых, далеко не все веб-мастера ведут свои архивы. Знать место, где можно найти информацию, которая была на сайте в какой-то момент, а потом пропала, не просто полезно, а очень важно.
В-третьих, само по себе сравнение является важнейшим методом анализа, который позволяет оценить ход и результаты нашей деятельности. Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Поэтому наличие уникальнейшего архива веб-страниц интернета позволяет нам получить доступ к огромному количеству аудио-, видео- и текстовых материалов. По утверждению разработчиков, «интернет-архив» хранит больше материалов, чем любая библиотека мира. Мы попали в правильное место!
Что нужно, чтобы найти копии сайтов интернета?
Для того, чтобы отправиться в прошлое, нужно перейти на сайт https://web-beta.archive.org/ и воспользоваться поисковой строкой.
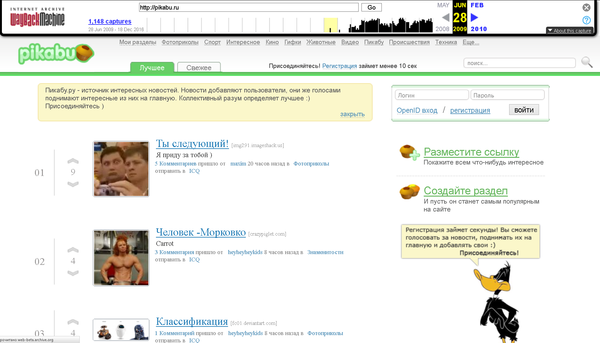
Простой поиск в архиве сохраненных сайтов выдает нам ссылки на все сохраненные копии запрашиваемой страницы.
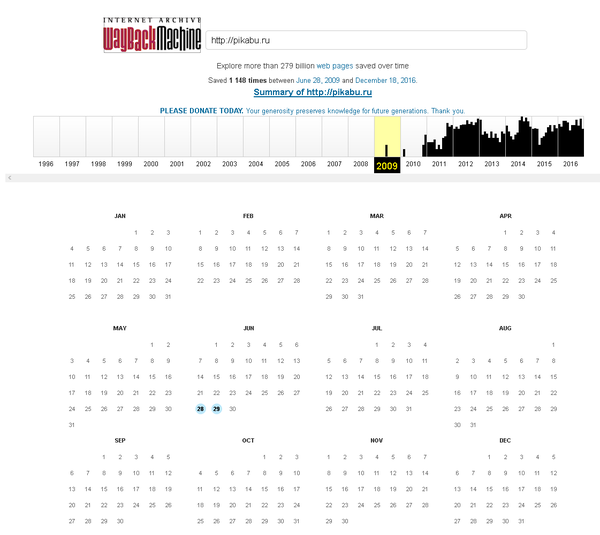
Из этого скриншота видно, что сайт http://pikabu.ru был создан в 2009 году. Переключаясь на нужный нам год, можно увидеть даты, выделенные кружочками, это и есть даты сохранения копии сайта. Например, в 2009 году, пока можно будет увидеть только две копии от 28 и 29 июня.
Конечно, это потрясающий ресурс! Ведь здесь индексируются и архивируются все сайты интернета! Это не только скриншоты… Имея в руках такой инструмент, можно восстановить массу потерянной со временем информации.
Надо заметить, что, безусловно все восстановить однозначно не получится, так как если на страницах сайта используются элементы Java Script, или скрипты или графика взяты со стороннего сервера, то на восстановление такой информации рассчитывать не придется. Поэтому к сохранению данных своего сайта нужно относиться с особенным вниманием, несмотря ни на что.